再也不用手动给照片打标签。
VisionTagger 使用设备端 AI 为你的图片批量生成标题、描述、关键词等元数据——无需上传,无按张收费。
需要运行 macOS 26 的 Apple Silicon Mac

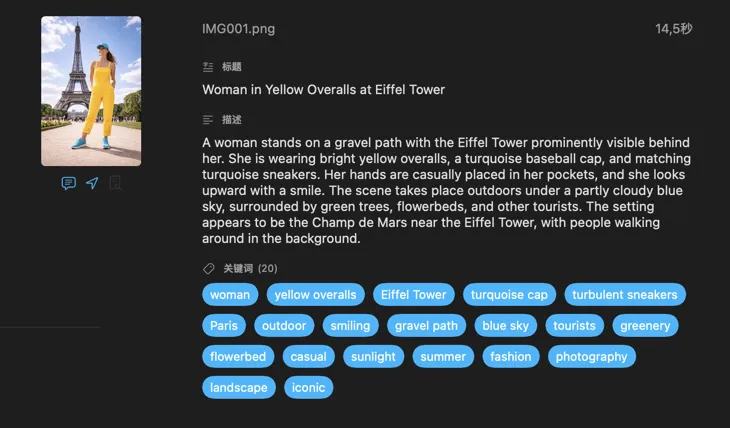


VisionTagger 适合谁?
-
拥有数千张未标记照片的摄影师 — 批量处理整组拍摄并导出带关键词、说明等的 XMP sidecar——可直接导入 Lightroom、Capture One 或 Photo Mechanic。
-
总是找不到那张照片的人 — 生成可搜索的标题、描述和 Finder 标签,让你图库中的每张图片都能被找到——现在,以及多年以后。
-
需要大批量生成替代文本的 Web 团队 — 为成百上千的网站图片生成准确、一致的替代文本——提升无障碍与 SEO,无需上传至第三方服务。
-
在项目素材中搜索的设计师 — 按情绪、风格、主题和用途为图片打标签,让你的素材库即时可搜索。
-
保存收藏的研究人员和档案工作者 — 为数据集、记录和长期数字保存创建结构化、一致的元数据。
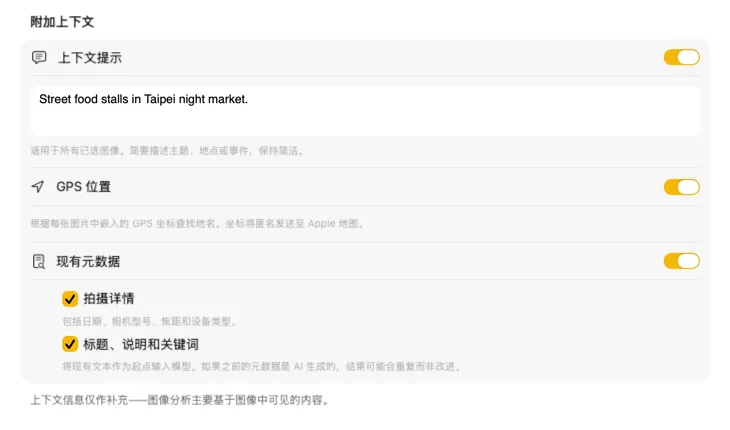
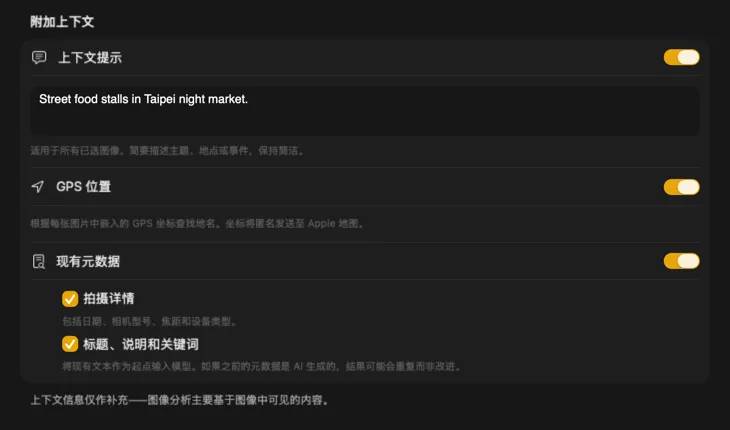
用已有的上下文获得更智能的结果
告诉 AI 它在看什么,结果会显著提升。添加一个 Context Hint,比如“复古家具店的产品照片”;开启 GPS Location,根据嵌入的坐标获取地名;或者把文件中已有的相机和编辑元数据一起传给模型。每个来源都是可选的,直接注入提示词——这样 AI 就不需要猜测了。
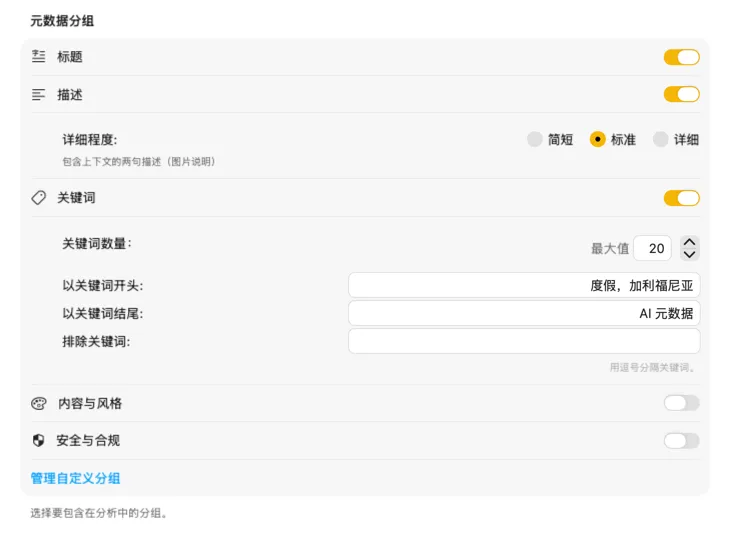
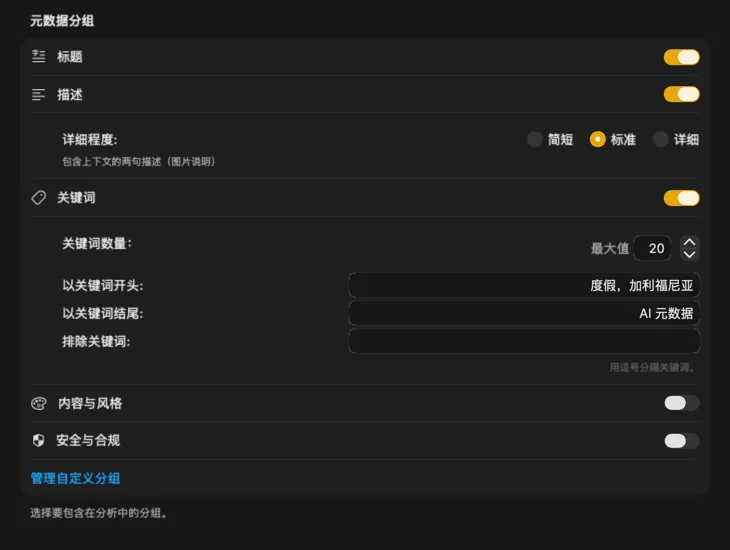
精确生成你需要的元数据
从大多数人需要的字段开始——标题、描述和关键词——然后用内容与风格、安全与合规进一步扩展,或添加完全自定义的分区和字段并编写自己的提示词。需要其他语言的输出?VisionTagger 可以使用 macOS 内置翻译功能自动翻译生成的元数据。最终得到的是跨数千张照片的结构化、一致的元数据。
无缝融入你的工作流
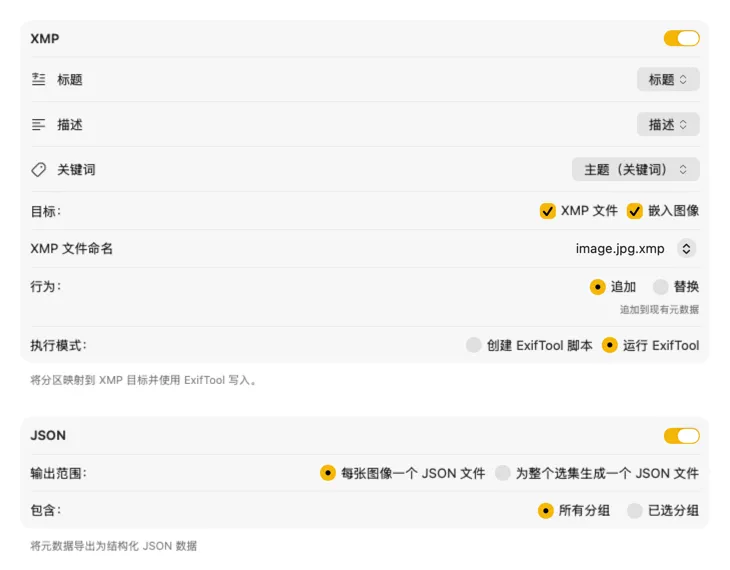
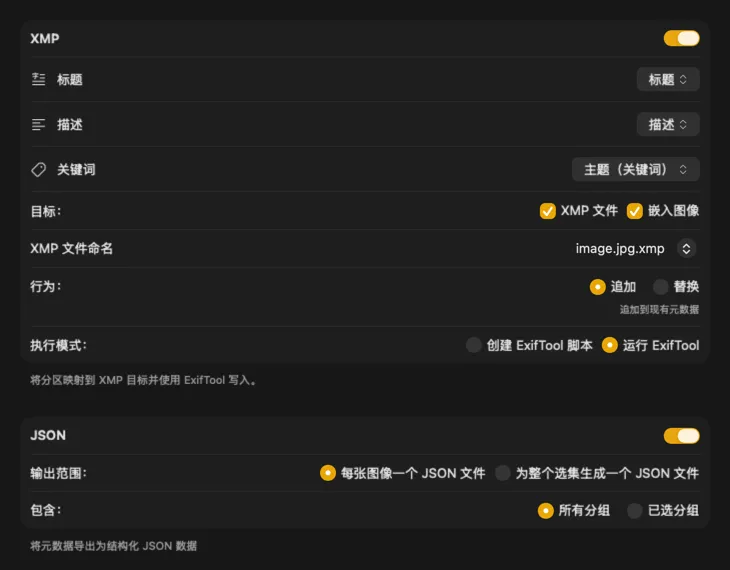
对于 XMP sidecar 和嵌入式元数据,VisionTagger 集成了 ExifTool——一个行业标准、广受信赖的工具。你的元数据会出现在 Adobe Lightroom、Bridge、Capture One、Photo Mechanic 等应用,以及任何读取 XMP 的其他软件中。写回你的 Photos Library,按图片导出 JSON、CSV 或 TXT,或为整次运行生成一个单文件。添加 Finder 标签,便于在 macOS 里快速整理。支持一次选择多个输出并统一配置——这样一次生成就能同时喂给你使用的每个目的地。
自动化,然后忘掉它
两个快捷指令操作——一个用于 Finder 中的文件,一个用于你的 Photos Library——让你无需打开应用就能在后台运行完整流程。设置文件夹自动化、Finder 快速操作,或从命令行触发。使用应用当前的设置,或提供一个保存的预设来获得每次都可复现的结果。


使用方法
在 YouTube 上观看演示
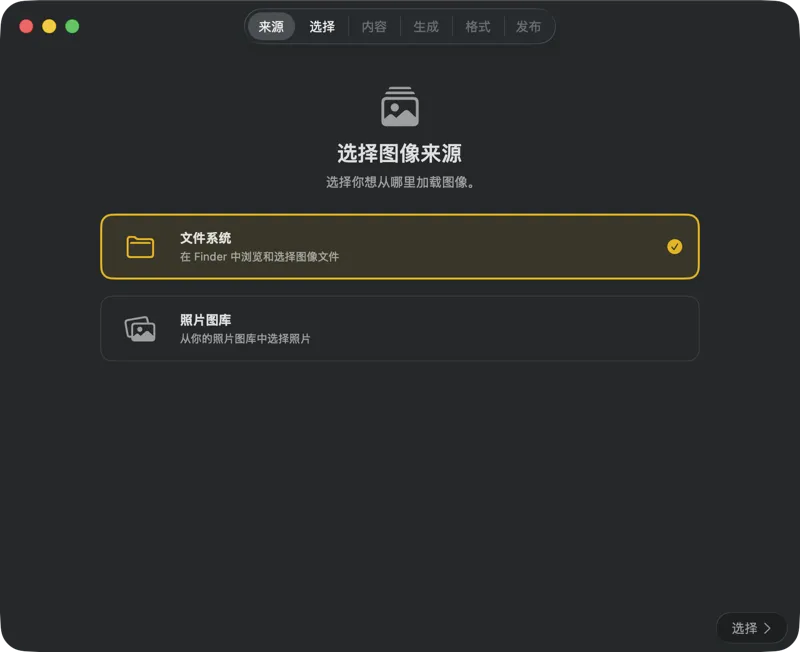
选择你的图片存放位置——Mac 上的文件夹,或你的 Photos Library。
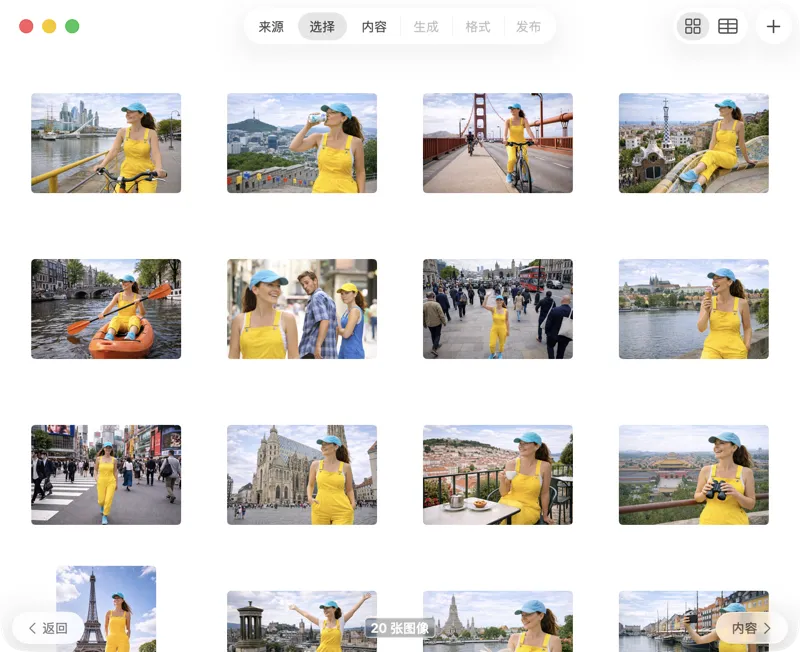
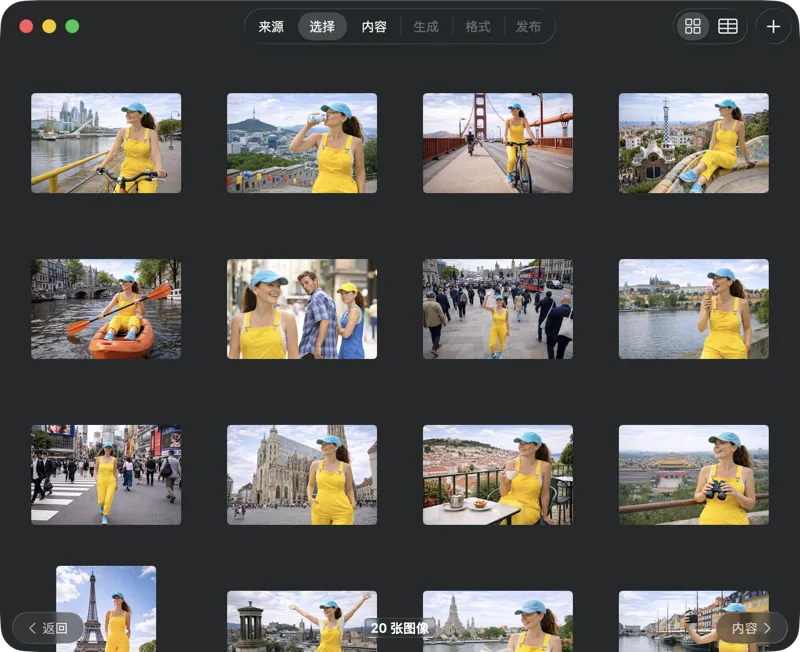
只挑你想处理的内容。你可以用网格或表格视图浏览所选内容,用添加按钮再加图片,或把文件拖拽到应用里来组一个批次。
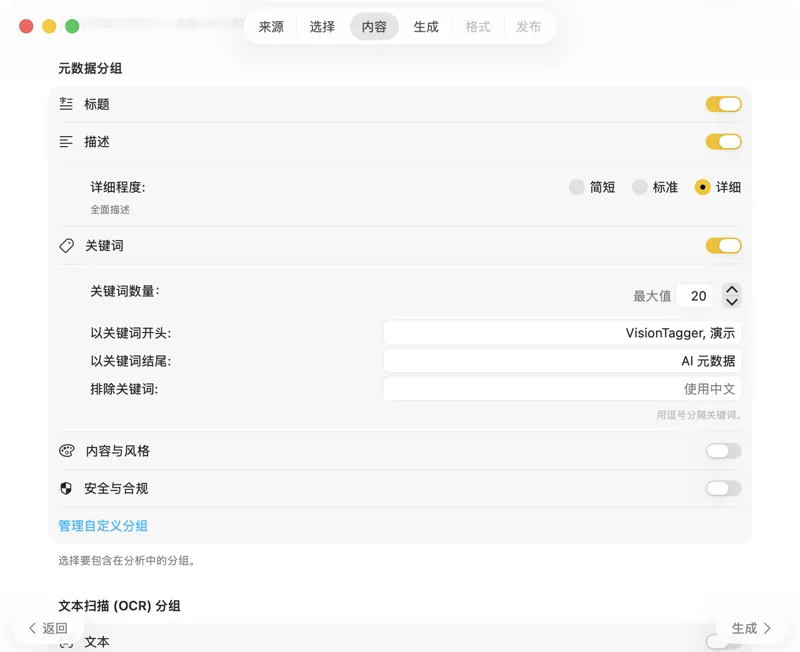
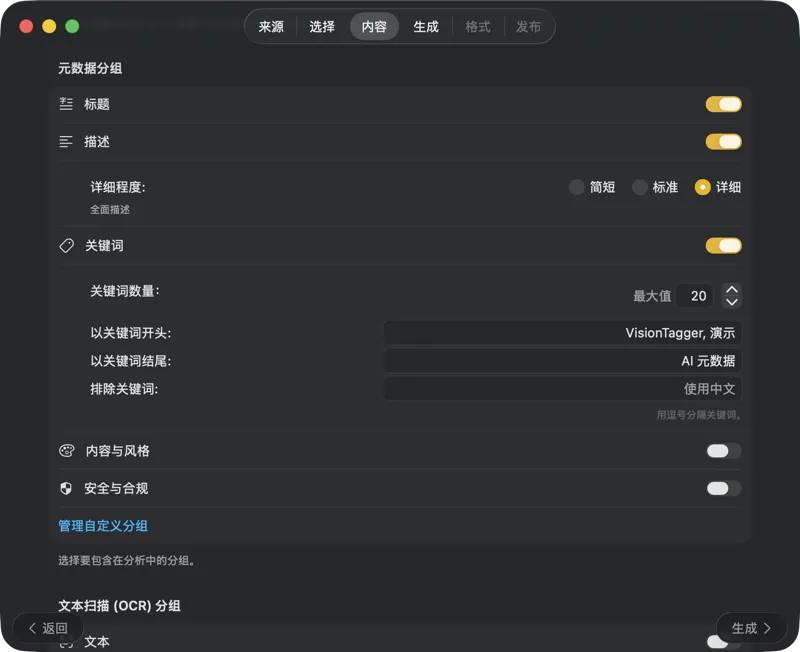
选择 AI 模型(在应用内一键下载),然后选择要生成哪些元数据:标题、描述、关键词、风格标签、安全评级,或你自己的自定义字段。
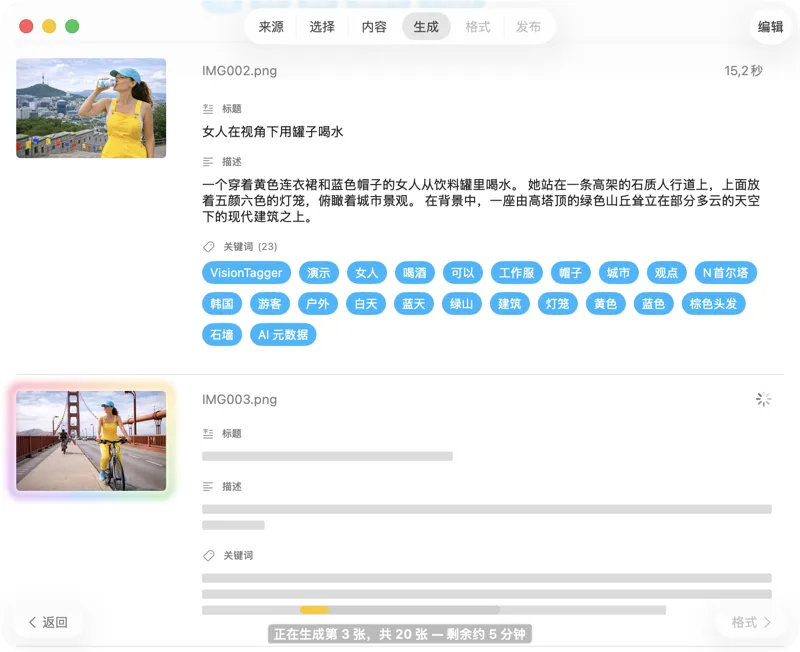
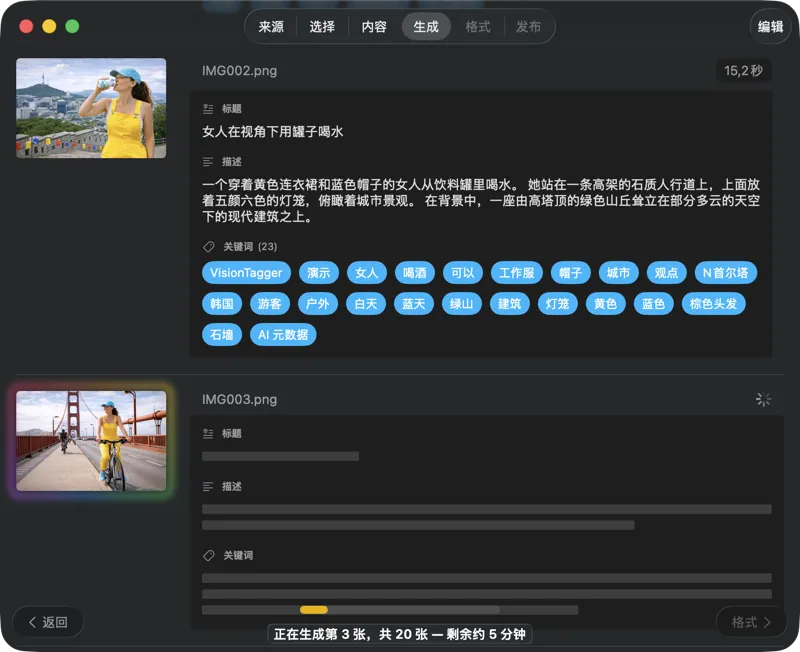
看结果实时出现。VisionTagger 在本地处理图片,并在每个项目准备好时立刻把生成的元数据流式写入一个可滚动列表,这样批处理还在继续时,你也能一边查看、一边编辑输出。
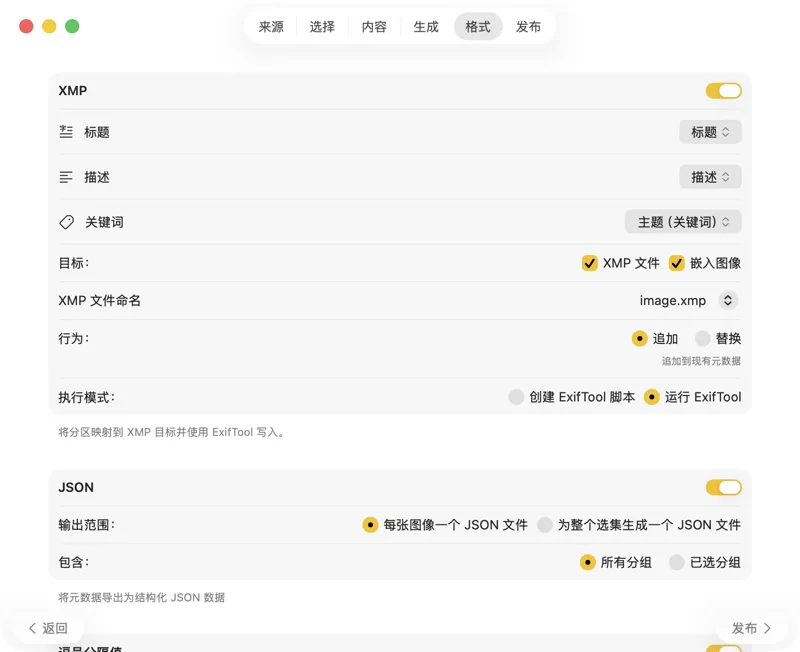
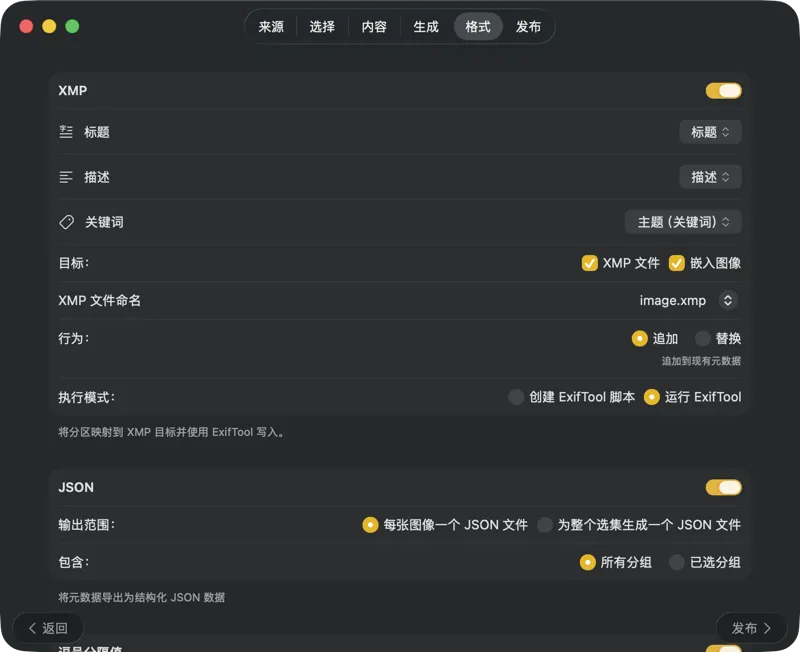
选择元数据的输出方式:XMP sidecar 用于你的照片目录,JSON 或 CSV 用于网站工作流,Finder 标签,或写回 Photos。支持一次选择多个输出。
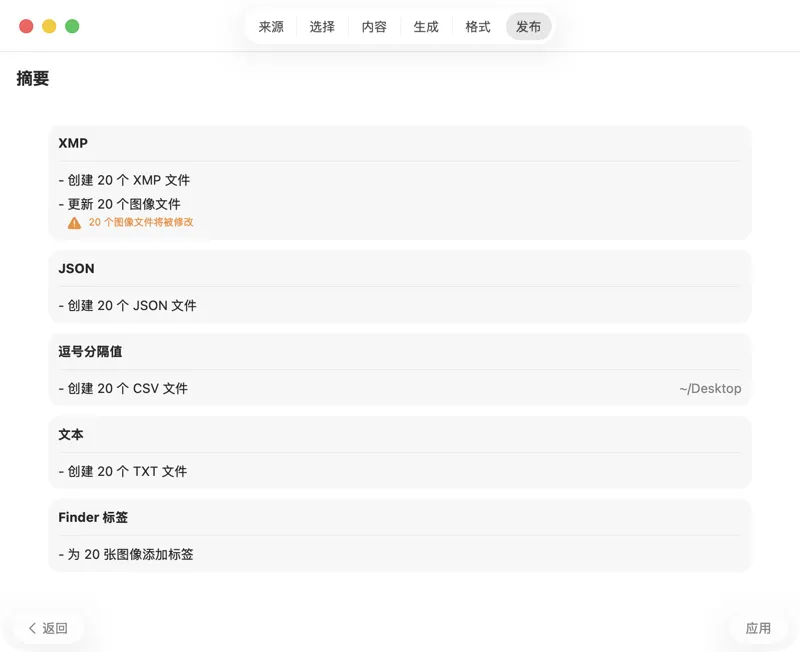
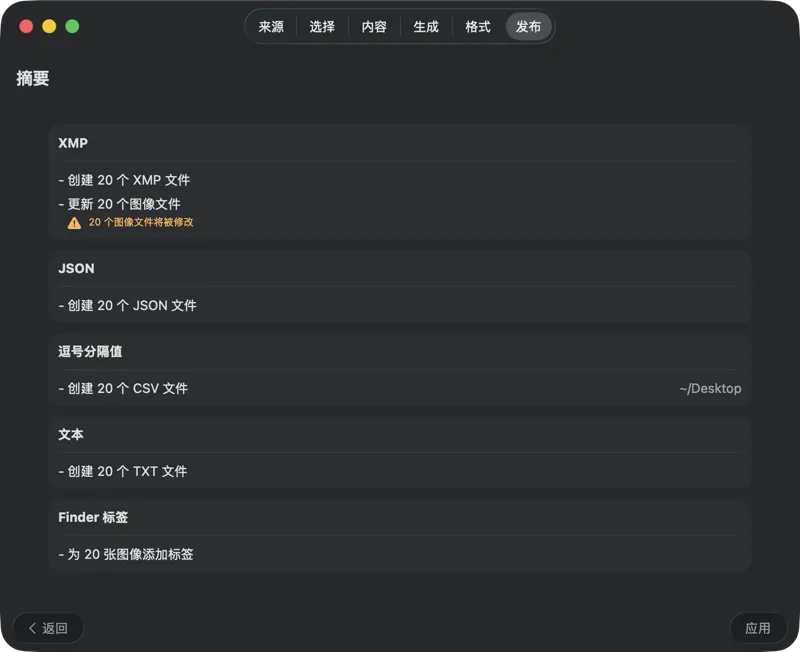
在写入任何内容之前先确认。查看将要执行的所有操作的清晰摘要,包括在可能覆盖现有文件或元数据时的警告——然后再发布,放心地应用你选择的输出。
一次性购买
已含增值税(US & CA 除外)
通过 FastSpring 安全付款