Fotos nie wieder manuell taggen.
VisionTagger nutzt On-Device-KI, um Titel, Beschreibungen, Keywords und mehr für deine Bilder zu erzeugen — in Batches, ohne Uploads und ohne Kosten pro Bild.
Benötigt einen Apple Silicon-Mac mit macOS 26

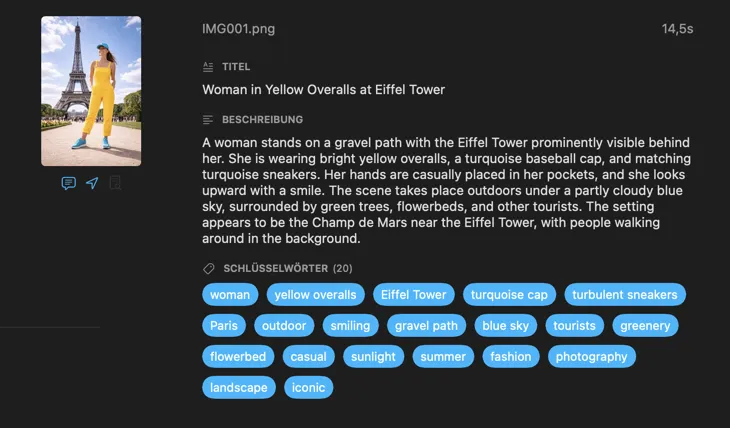
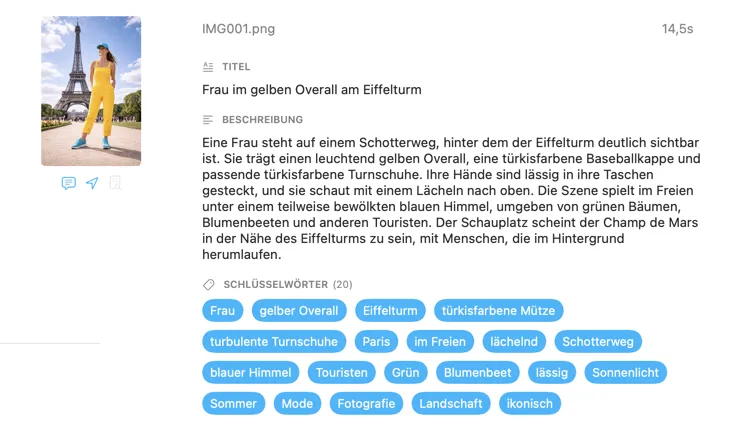
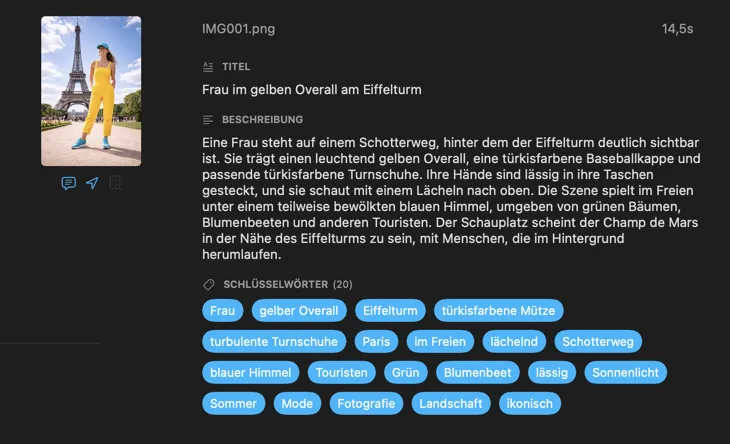
Für wen ist VisionTagger?
-
Designer*innen, die in Projektdateien suchen — Tagge Bilder nach Stimmung, Stil, Motiv und Verwendung, um deine Asset-Bibliothek sofort durchsuchbar zu machen.
-
Forscher*innen und Archivar*innen, die Sammlungen bewahren — Erstelle strukturierte, konsistente Metadaten für Datensätze, Aufzeichnungen und die langfristige digitale Archivierung.
Präzisere Ergebnisse durch vorhandenen Kontext
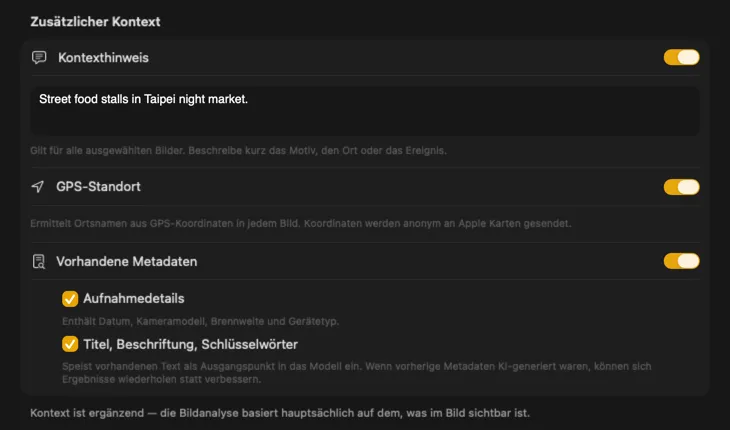
Gib der KI Kontext zu deinen Bildern, um die Ergebnisse drastisch zu verbessern. Füge Hinweise hinzu wie „Produktfotos für einen Vintage-Möbelladen“, aktiviere den GPS-Standort, um Ortsnamen aus Koordinaten zu ermitteln, oder nutze vorhandene Kamera- und Redaktions-Metadaten. Jede Quelle ist optional und fließt direkt in den Prompt ein – damit die KI nicht raten muss.
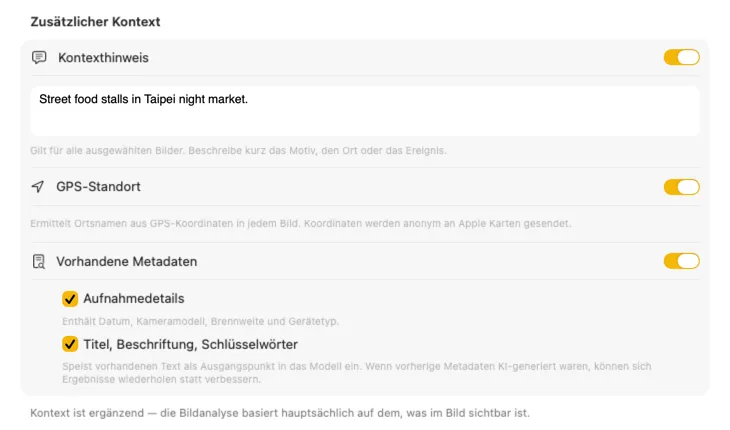
Erstelle genau die Metadaten, die du benötigst
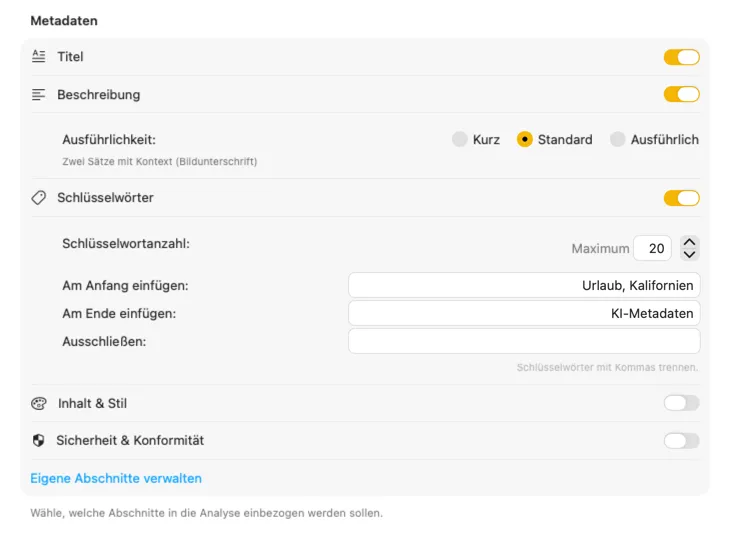
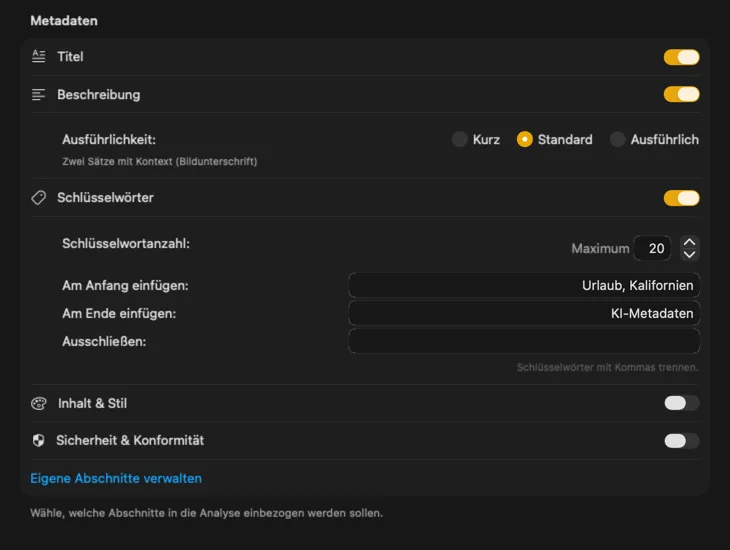
Beginne mit Standardfeldern wie Titel, Beschreibung und Keywords und erweitere sie um Stil, Sicherheit oder komplett eigene Sektionen mit individuellen Prompts. Du benötigst die Ausgabe in einer anderen Sprache? VisionTagger kann Metadaten automatisch mit der systemweiten macOS-Übersetzung lokalisieren. Das Ergebnis sind strukturierte, konsistente Metadaten für tausende Fotos.
Nahtlose Integration in deinen Workflow
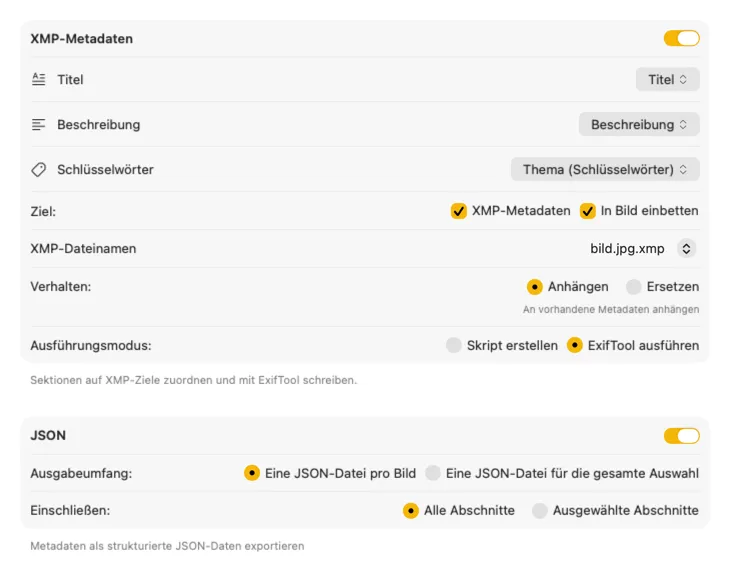
Für XMP-Sidecars und eingebettete Metadaten nutzt VisionTagger das bewährte ExifTool. Deine Metadaten erscheinen sofort in Adobe Lightroom, Capture One, Photo Mechanic und jeder anderen Software, die XMP unterstützt. Schreibe direkt in die Fotos-Mediathek, exportiere JSON/CSV/TXT pro Bild oder als Sammeldatei. Nutze Finder-Tags für die Organisation in macOS und bediene mehrere Ziele gleichzeitig in einem Durchlauf.
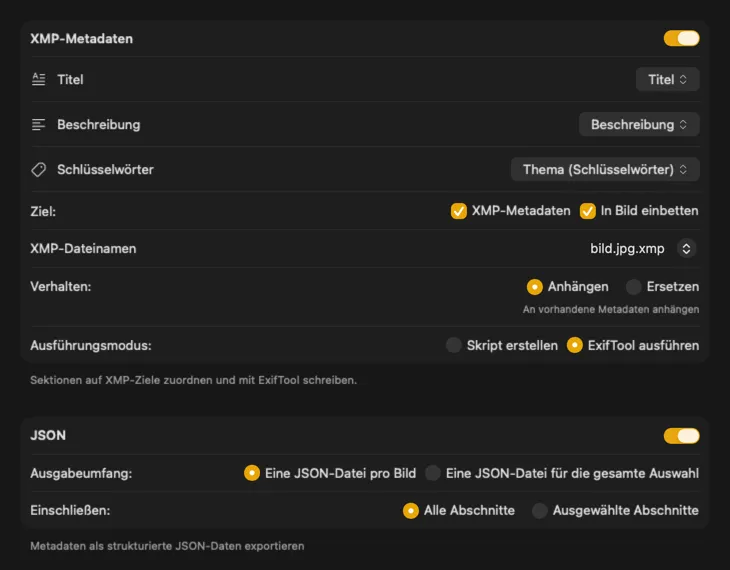
Automatisieren und Zeit sparen
Zwei Kurzbefehle-Aktionen – für den Finder und die Fotos-Mediathek – ermöglichen die Verarbeitung im Hintergrund, ohne die App zu öffnen. Erstelle Ordnerautomatisierungen, Schnellaktionen oder nutze die Kommandozeile. Verwende die aktuellen App-Einstellungen oder gespeicherte Presets für konsistente, jederzeit reproduzierbare Ergebnisse.


So funktioniert’s
Demo auf YouTube ansehen
Wähle den Speicherort deiner Bilder — Ordner auf deinem Mac oder deine Fotos-Mediathek.
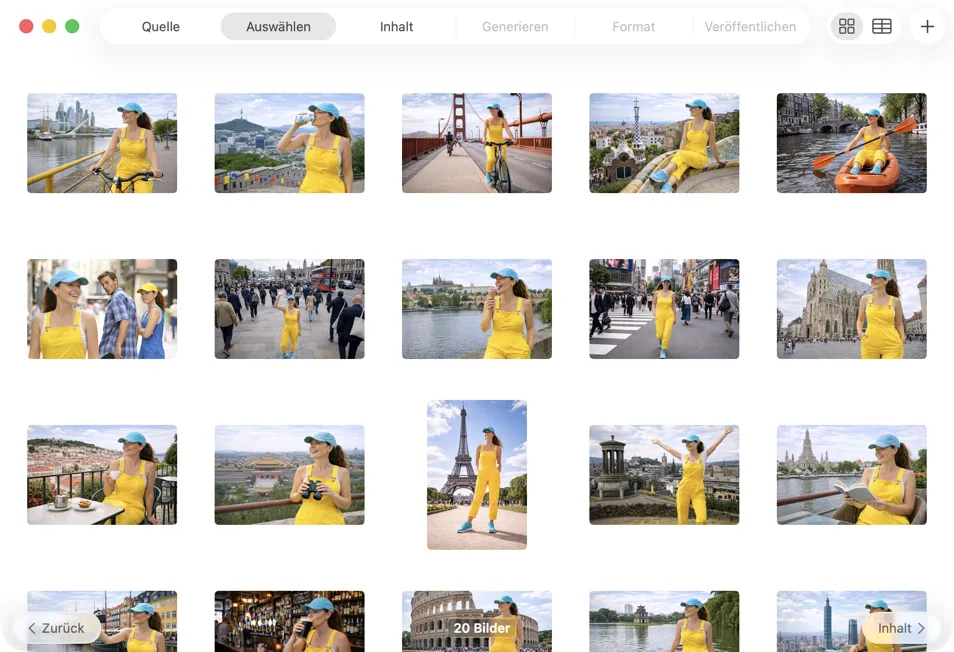
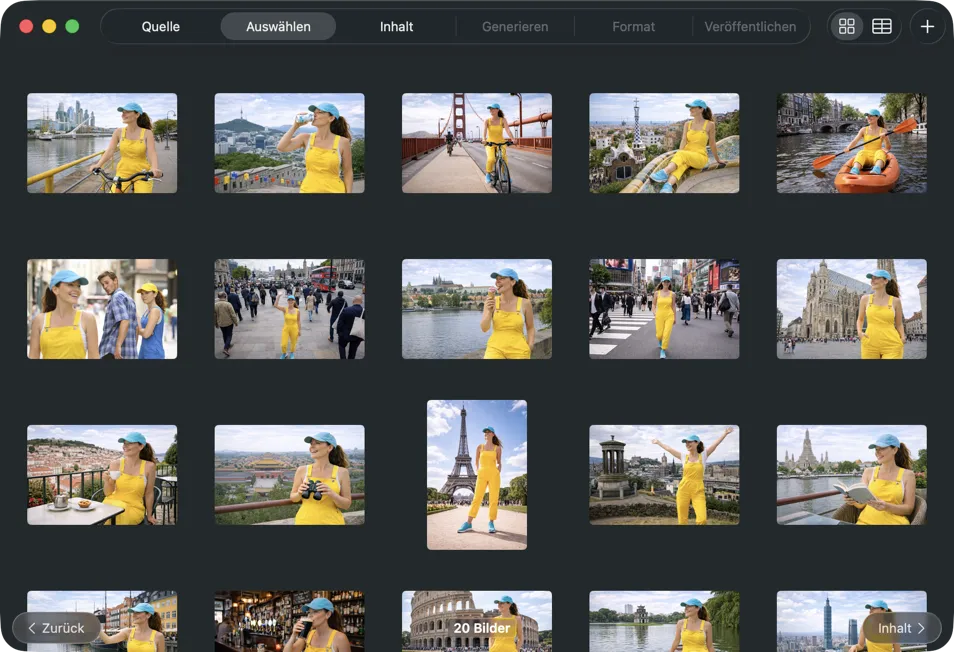
Wähle genau aus, was du verarbeiten willst. Nutze die Raster- oder Tabellenansicht, füge Bilder über den Button hinzu oder ziehe Dateien per Drag & Drop direkt in die App.
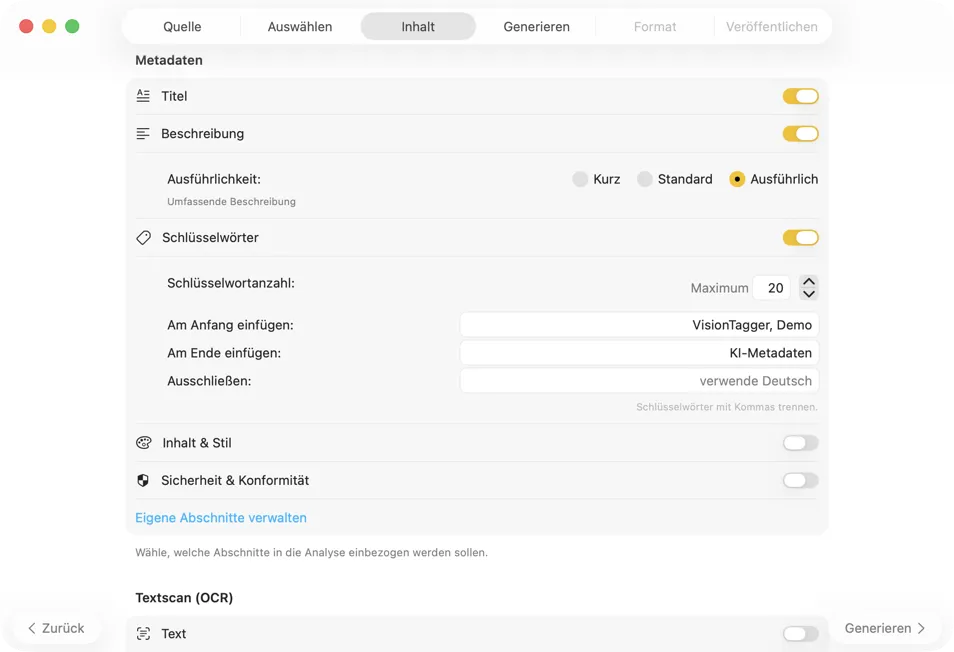
Wähle ein KI-Modell und bestimme, welche Metadaten generiert werden sollen: Titel, Beschreibungen, Keywords, Stil-Tags, Sicherheitsbewertungen oder eigene benutzerdefinierte Felder.
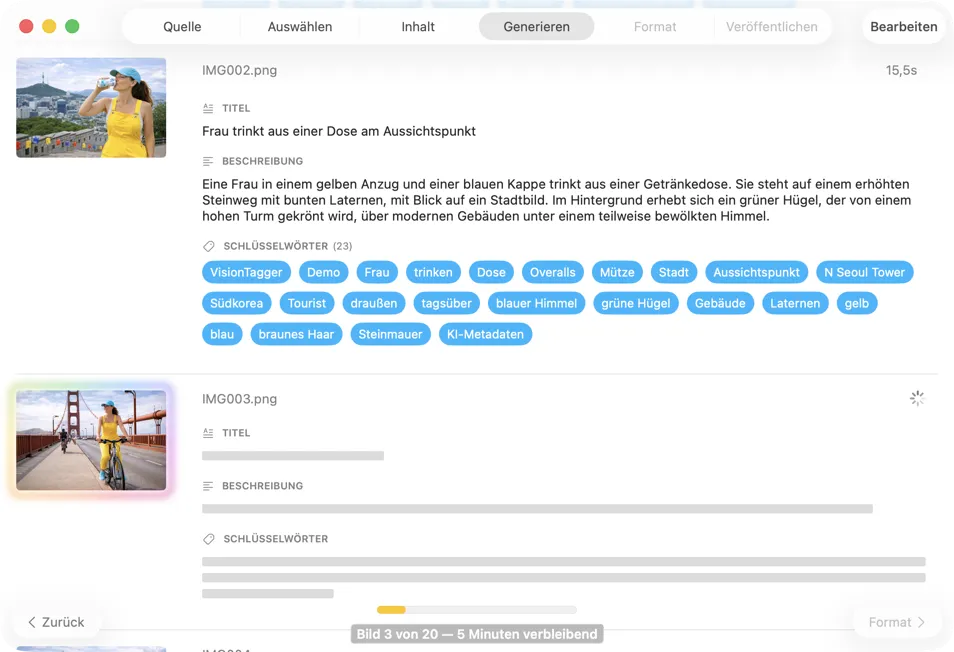
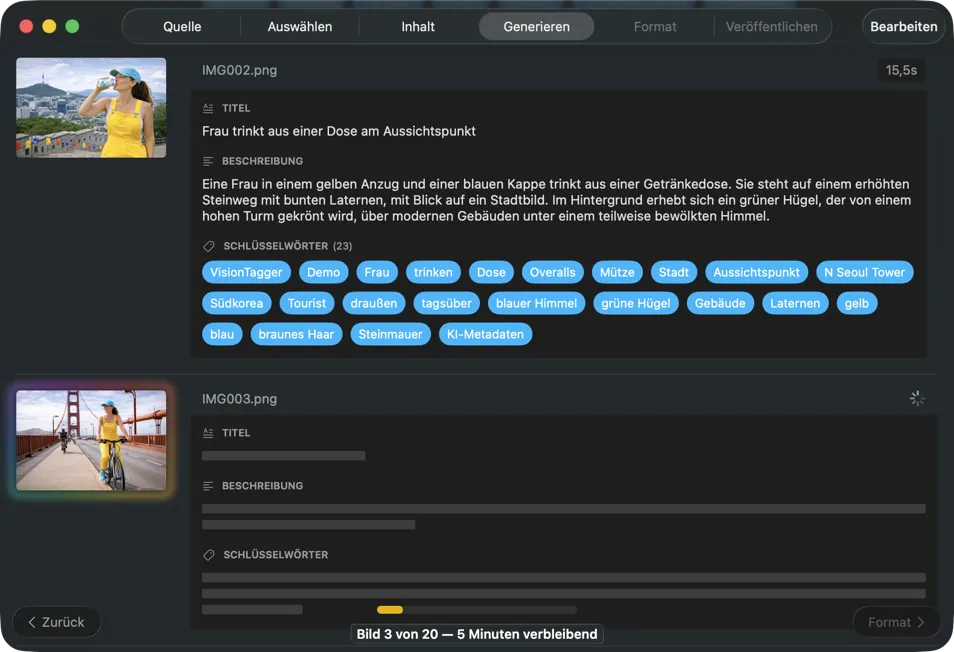
Erlebe die Ergebnisse in Echtzeit. VisionTagger verarbeitet Bilder lokal und zeigt generierte Metadaten sofort an, sodass du sie prüfen und bearbeiten kannst, während der Batch noch läuft.
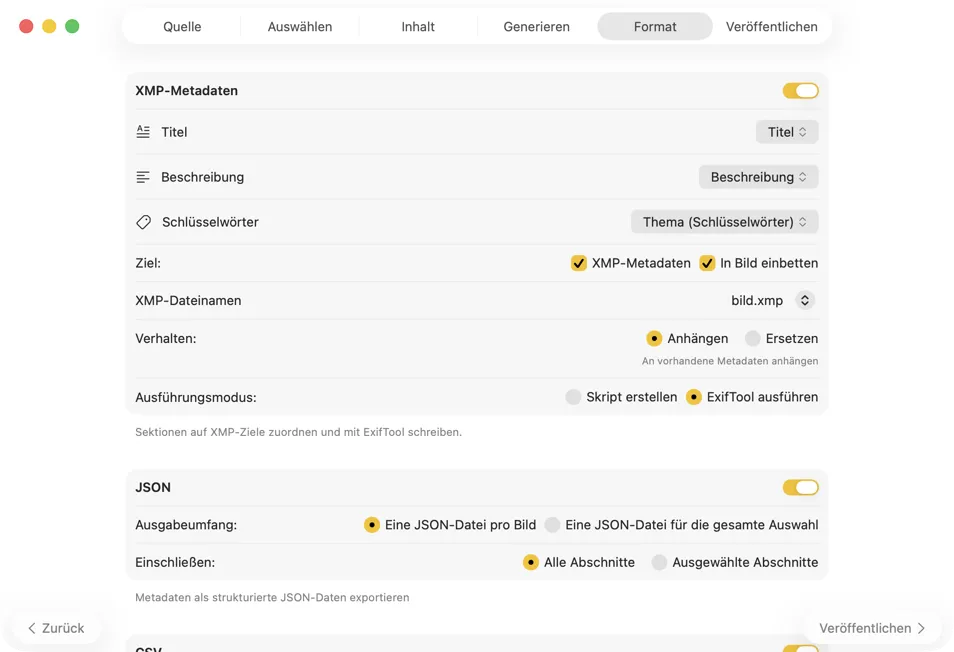
Wähle das Ziel: XMP-Sidecars für Fotokataloge, JSON/CSV für Web-Pipelines, Finder-Tags oder direktes Schreiben in die Fotos-App. Wähle mehrere Formate gleichzeitig.
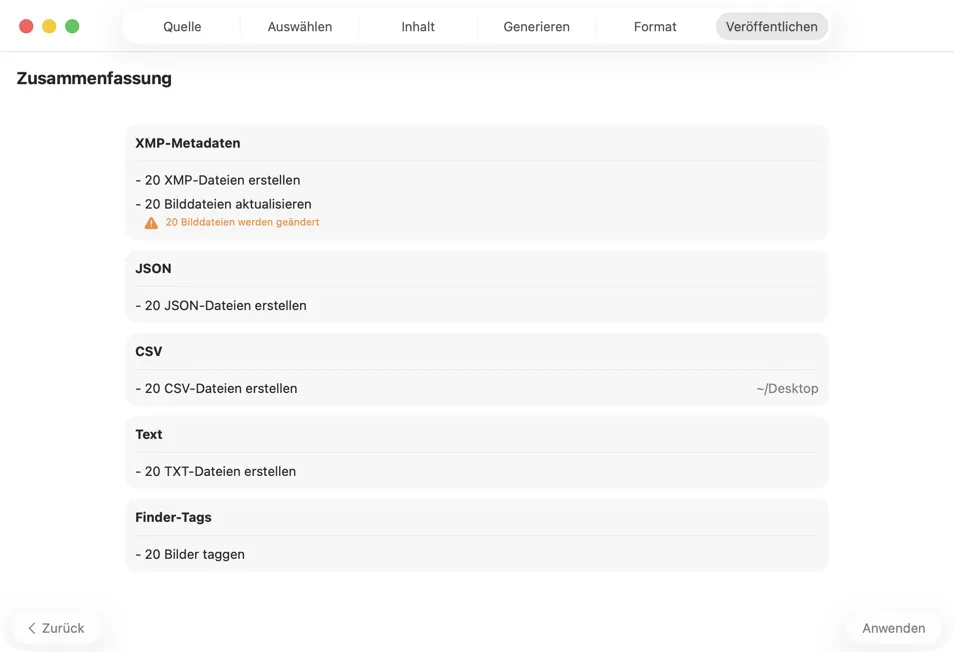
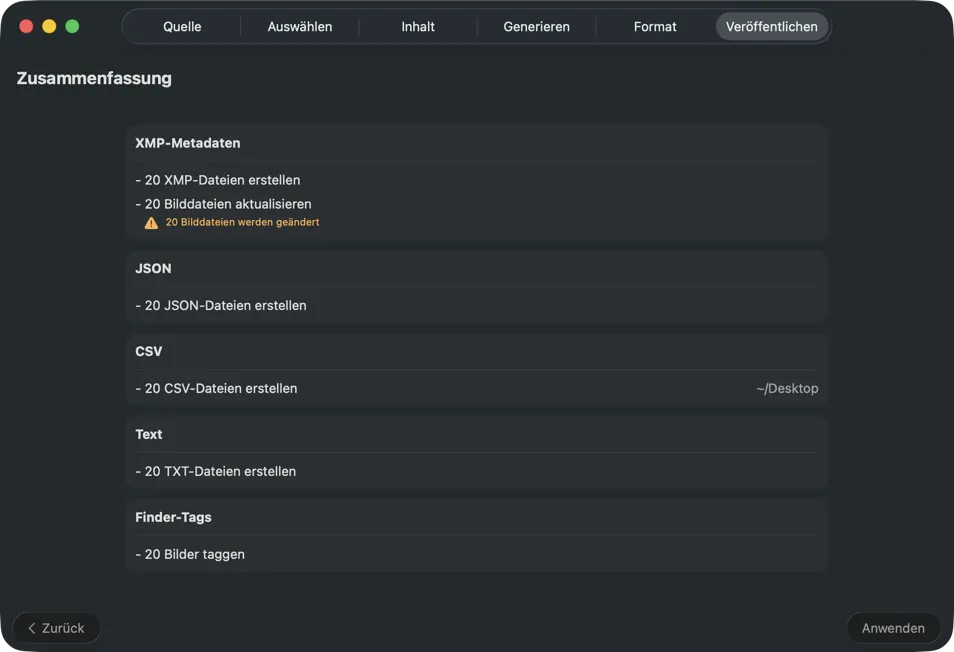
Prüfe alles vor dem Speichern. Eine klare Zusammenfassung zeigt alle Aktionen und warnt vor dem Überschreiben vorhandener Daten – für ein sicheres Anwenden deiner Ergebnisse.
Einmalkauf
MwSt. inklusive
Sichere Zahlung über FastSpring