사진 태그, 더 이상 수작업은 그만.
VisionTagger는 온디바이스 AI로 이미지의 제목, 설명, 키워드 등을 일괄 생성해요 — 업로드도, 이미지당 요금도 없이요.
macOS 26를 실행하는 Apple Silicon Mac이 필요해요

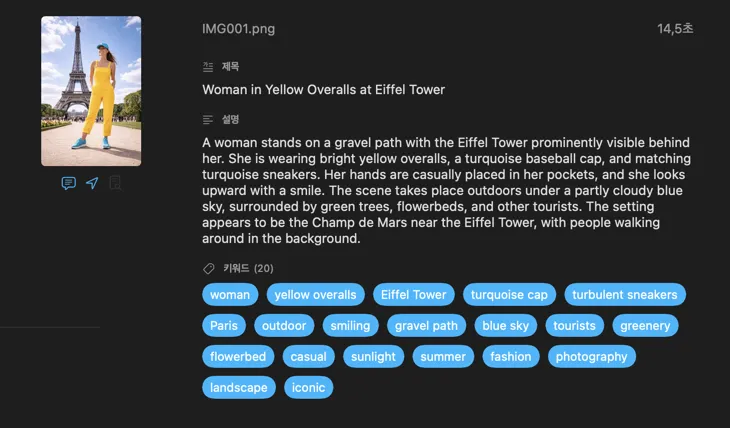

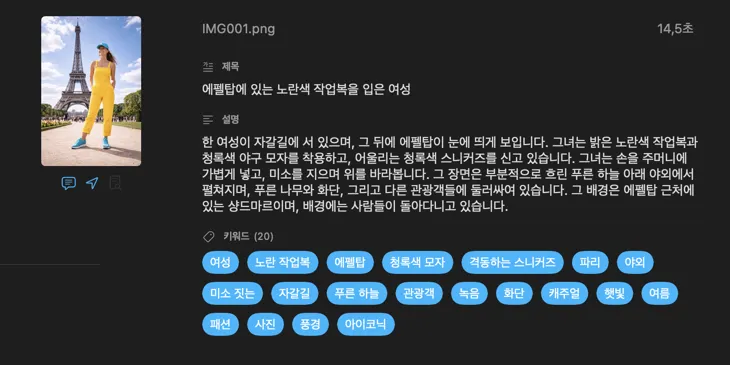
VisionTagger는 누구를 위한 앱인가요?
-
프로젝트 에셋을 검색하는 디자이너 — 이미지를 무드, 스타일, 주제, 사용 목적으로 태그해서 에셋 라이브러리를 즉시 검색 가능하게 만들어요.
-
컬렉션을 보존하는 연구자와 아키비스트 — 데이터셋, 기록, 장기 디지털 보존을 위해 구조적이고 일관된 메타데이터를 만들어요.
이미 가진 정보로 더 정확한 결과를
AI에게 무엇을 보고 있는지 알려주면 결과가 훨씬 좋아져요. “빈티지 가구 매장의 제품 사진”처럼 Context Hint를 추가하고, GPS Location을 켜서 내장된 좌표에서 장소 이름을 조회하거나, 파일에 이미 있는 카메라 및 편집 메타데이터를 전달할 수 있어요. 각 소스는 선택 사항이고 프롬프트에 직접 반영돼요 — 그래서 AI가 추측할 필요가 없어요.
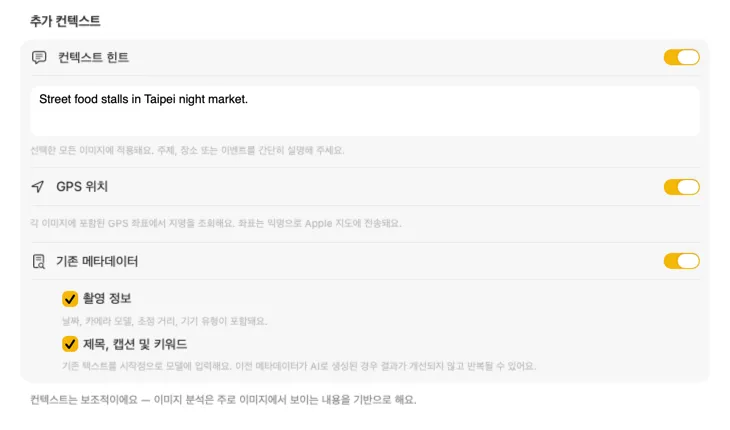
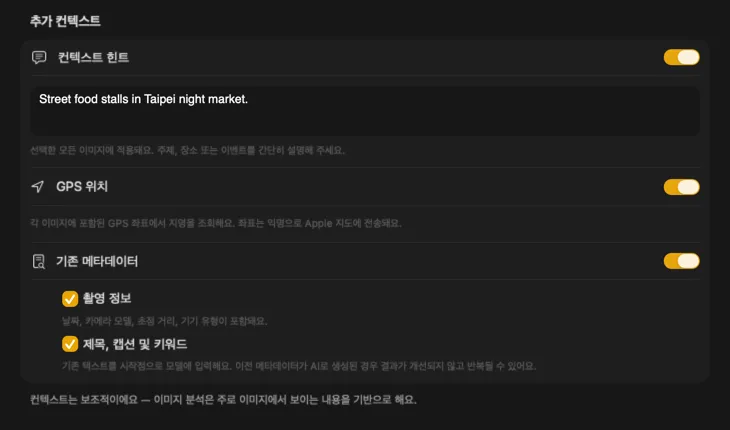
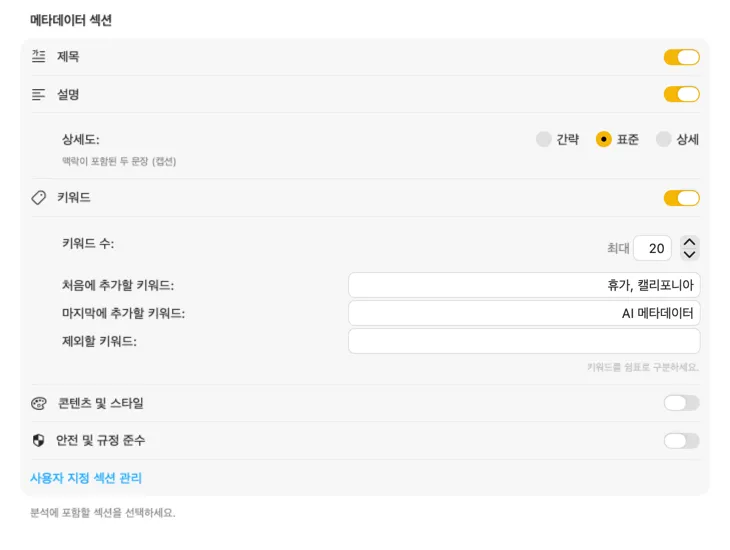
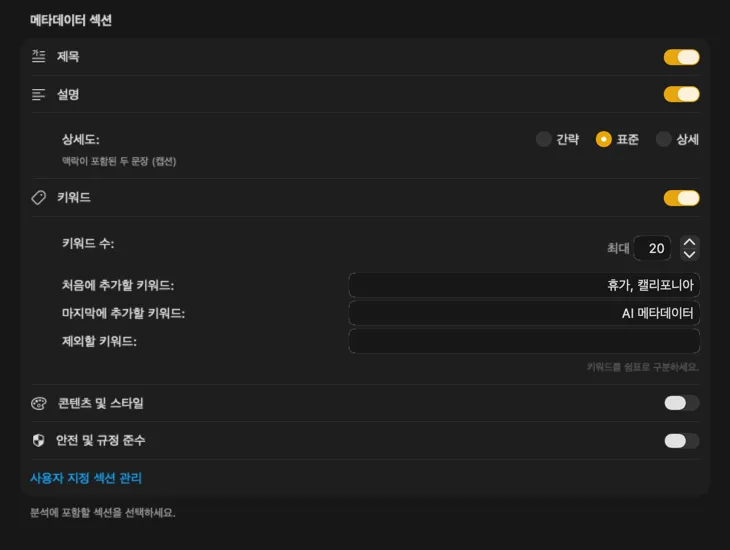
필요한 메타데이터를 정확히 생성해요
대부분의 사람이 필요로 하는 필드 — 제목, 설명, 키워드 — 부터 시작한 다음, 콘텐츠 및 스타일, 안전 및 컴플라이언스까지 확장하거나, 나만의 필드와 프롬프트로 완전히 커스텀 섹션을 추가할 수 있어요. 다른 언어로 출력이 필요해요? VisionTagger는 macOS 내장 번역 기능을 사용하여 생성된 메타데이터를 자동으로 번역할 수 있어요. 결과는 수천 장의 사진에 걸쳐 구조적이고 일관된 메타데이터예요.
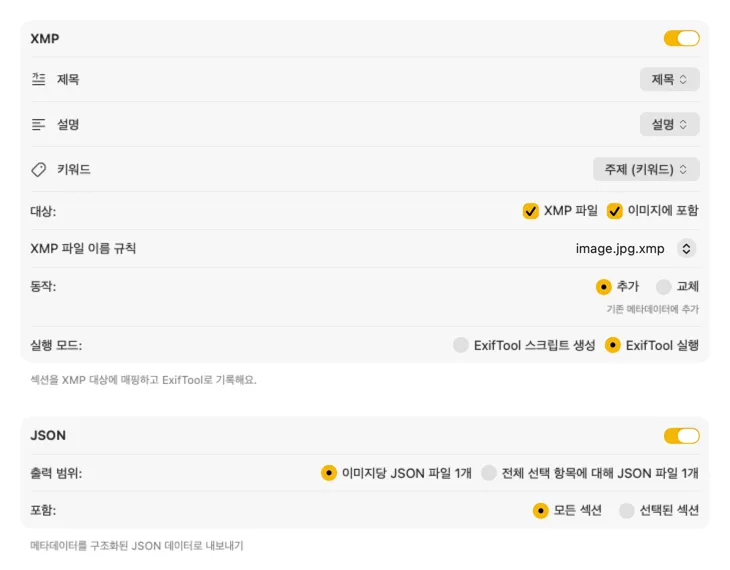
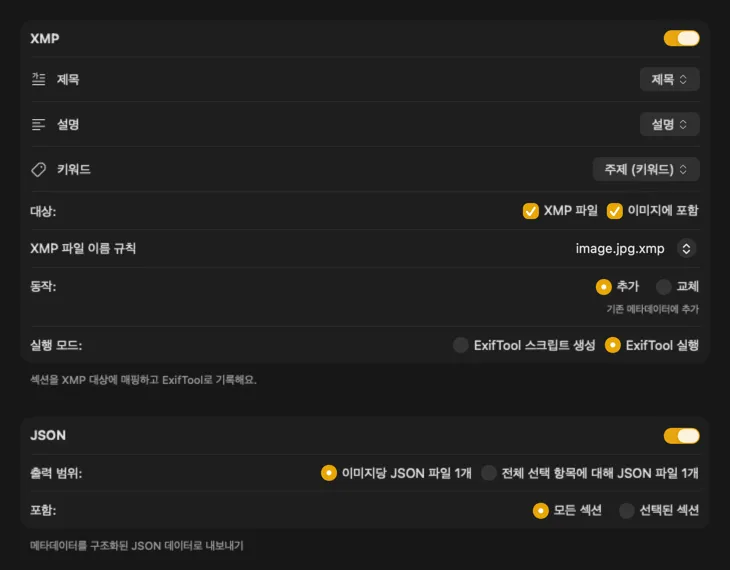
기존 워크플로에 바로 연결돼요
XMP 사이드카와 임베디드 메타데이터를 위해 VisionTagger는 ExifTool과 통합돼요 — 업계 표준이자 널리 신뢰받는 유틸리티예요. 메타데이터는 Adobe Lightroom, Bridge, Capture One, Photo Mechanic 같은 앱과 XMP를 읽는 다른 어떤 소프트웨어에서도 표시돼요. Photos Library에 다시 쓰거나, 이미지별로 JSON, CSV 또는 TXT를 내보내거나, 전체 실행에 대해 단일 파일을 생성할 수도 있어요. macOS에서 빠르게 정리할 수 있도록 Finder 태그도 추가해요. 여러 출력을 한 번에 선택하고 함께 설정할 수 있어서, 한 번의 생성 패스로 사용하는 모든 목적지로 보낼 수 있어요.
자동화하고 잊어버려요
두 가지 단축어 동작 — Finder의 파일용과 Photos Library용 — 으로 앱을 열지 않고도 전체 프로세스를 백그라운드에서 실행할 수 있어요. 폴더 자동화, Finder 빠른 동작을 설정하거나 명령어 줄에서 실행할 수도 있어요. 앱의 현재 설정을 그대로 쓰거나, 저장된 프리셋을 지정해서 매번 재현 가능한 결과를 얻을 수 있어요.


사용 방법
YouTube에서 데모 보기
이미지가 저장된 위치를 선택해요 — Mac의 폴더 또는 Photos Library요.
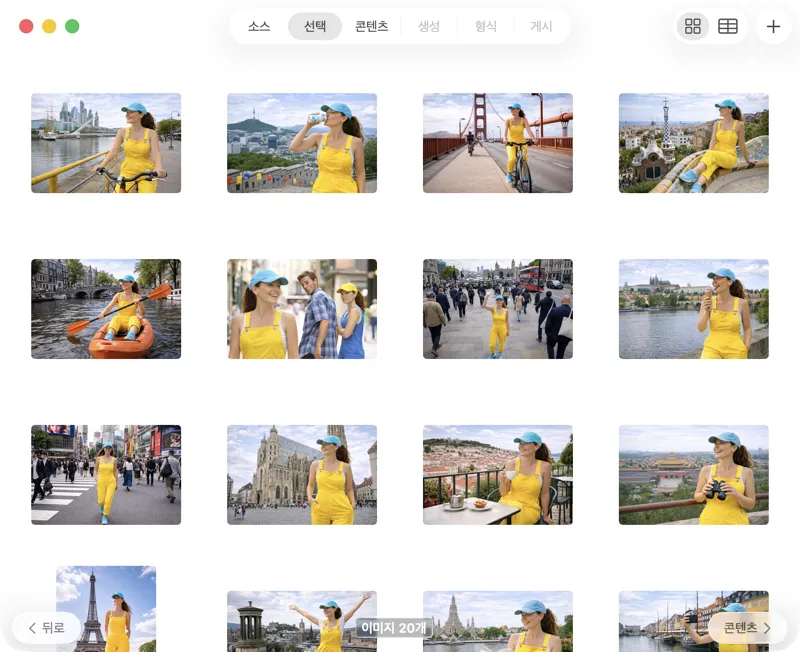
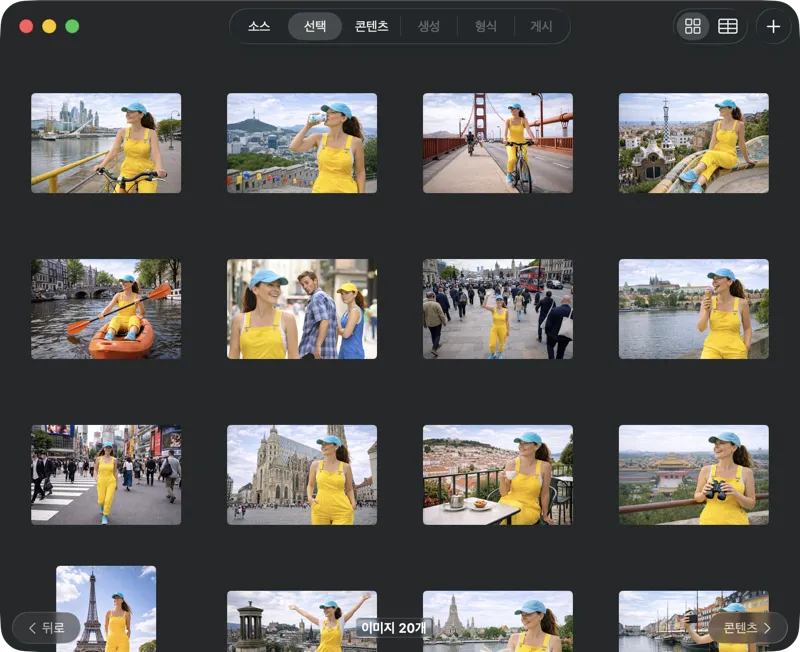
처리할 대상을 딱 필요한 만큼만 골라요. 그리드 또는 표 보기에서 선택 항목을 둘러보고, 추가 버튼으로 이미지를 더 넣거나, 파일을 앱으로 드래그 앤 드롭해서 배치를 만들 수 있어요.
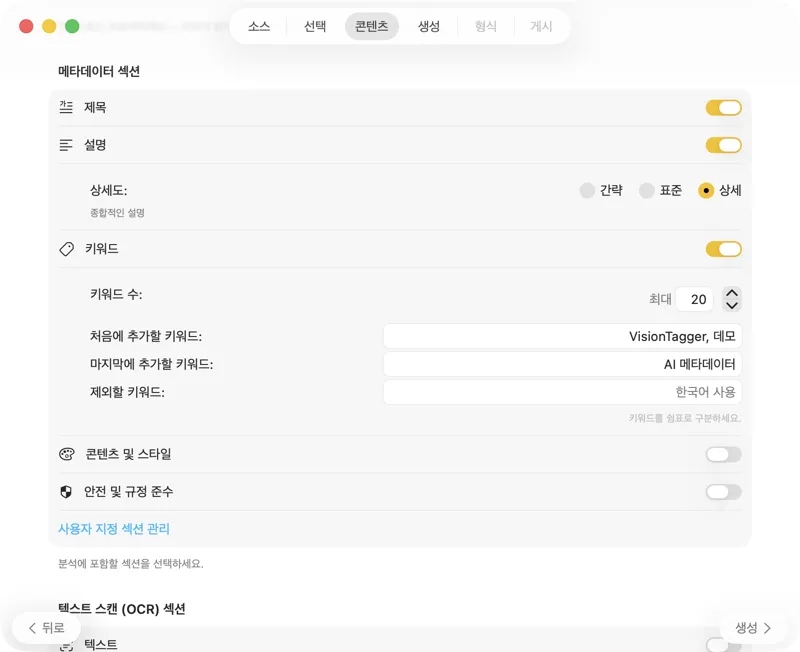
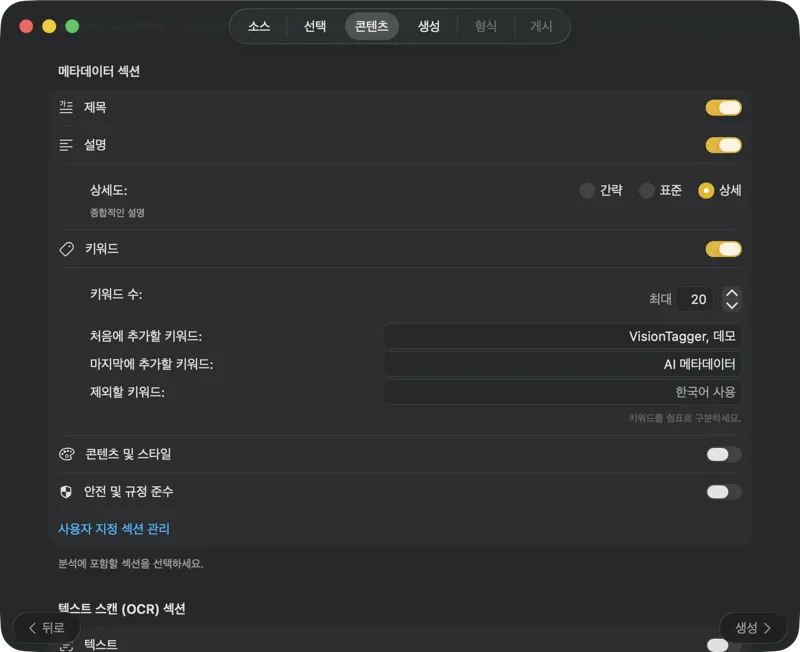
AI 모델을 선택하고(앱에서 클릭 한 번으로 다운로드), 어떤 메타데이터를 생성할지 고르세요: 제목, 설명, 키워드, 스타일 태그, 안전 등급, 또는 나만의 커스텀 필드까지요.
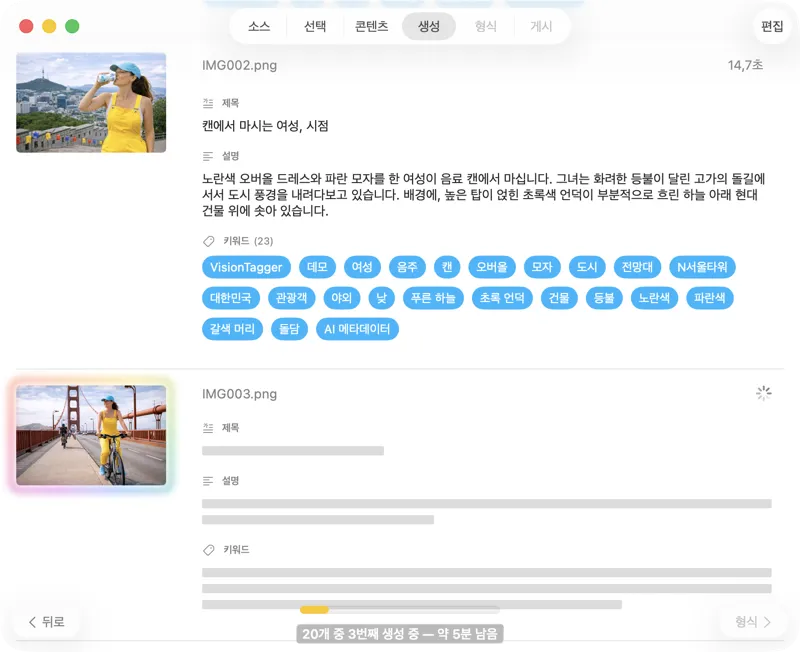
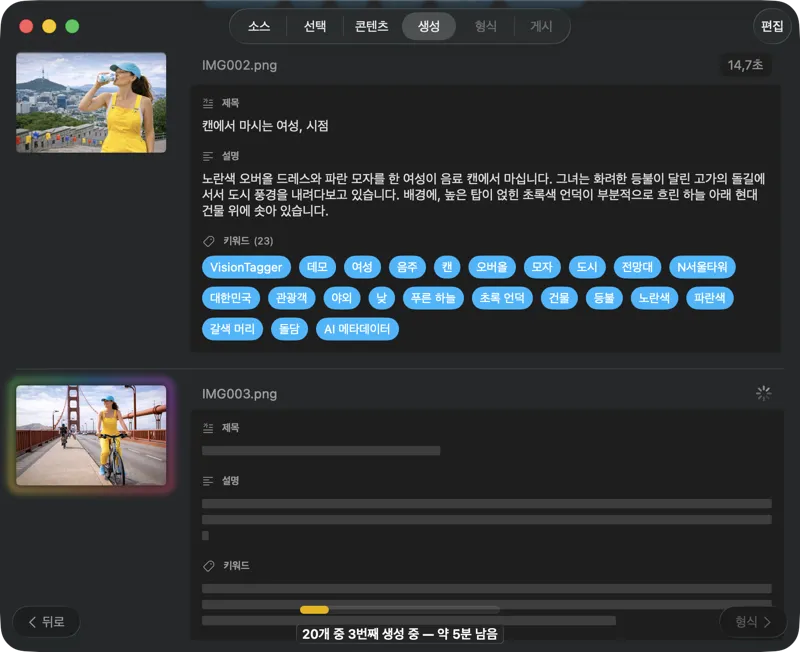
결과가 실시간으로 나타나는 걸 확인해요. VisionTagger는 이미지를 로컬에서 처리하고, 각 항목이 준비되는 즉시 생성된 메타데이터를 스크롤 목록으로 스트리밍해요. 그래서 배치가 계속 돌아가는 동안에도 출력물을 확인하고 수정할 수 있어요.
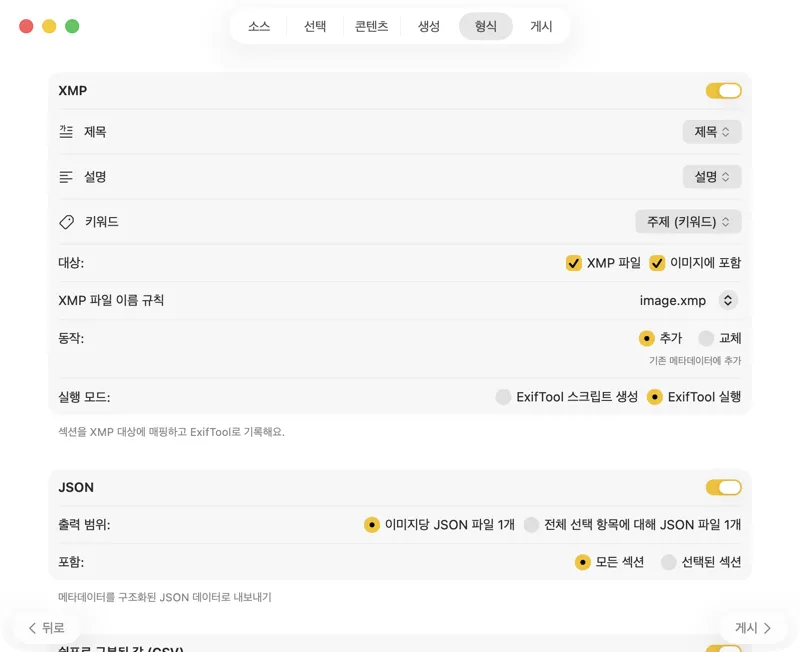
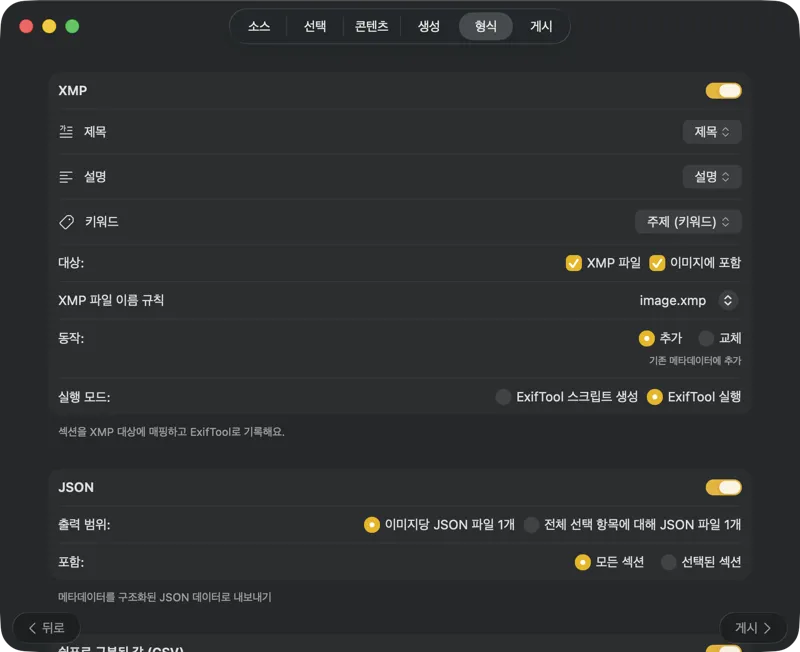
메타데이터가 어디로 가야 하는지 정해요: 포토 카탈로그용 XMP 사이드카, 웹사이트 파이프라인용 JSON 또는 CSV, Finder 태그, 또는 Photos에 다시 쓰기. 여러 출력을 한 번에 선택할 수 있어요.
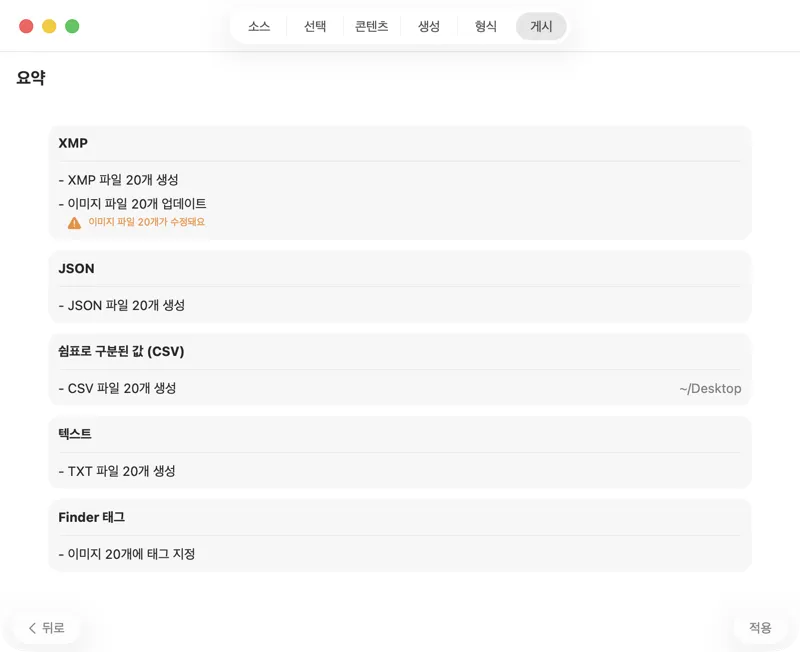
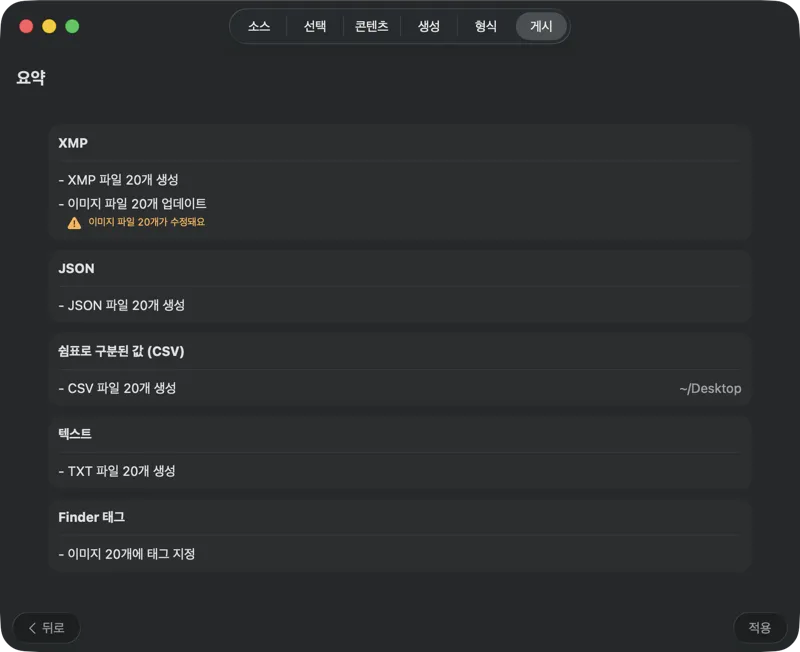
무엇이든 쓰기 전에 확인해요. 실행될 모든 작업을 한눈에 보는 요약을 검토하고, 기존 파일이나 메타데이터가 덮어써질 수 있을 때는 경고도 확인해요 — 그다음 자신 있게 게시해서 선택한 출력을 적용하면 돼요.
일회성 구매
VAT 포함 (US & CA 제외)
FastSpring을 통한 안전 결제