写真のタグ付け、もう手作業は不要。
VisionTagger はオンデバイスAIで、画像のタイトル、説明、キーワードなどを一括生成 — アップロードなし、1枚あたりの課金もなし。
macOS 26 の Apple Silicon Mac が必要



VisionTagger はこんな方に
-
あの一枚がどうしても見つからない人 — 検索できるタイトル、説明、Finder タグを生成して、ライブラリのどの画像も見つけられるようにする — 今日も、何年後も。
-
大量のaltテキストが必要なWebチーム — 何百枚ものWebサイト画像に対して正確で一貫したaltテキストを生成 — サードパーティサービスにアップロードせずにアクセシビリティとSEOを改善。
-
プロジェクトのアセットを横断検索したいデザイナー — ムード、スタイル、被写体、用途で画像をタグ付けして、アセットライブラリを即座に検索可能にする。
-
コレクションを保存する研究者・アーキビスト — データセット、記録、長期的なデジタル保存のために、構造化された一貫したメタデータを作成する。
手持ちのコンテキストでよりスマートな結果を
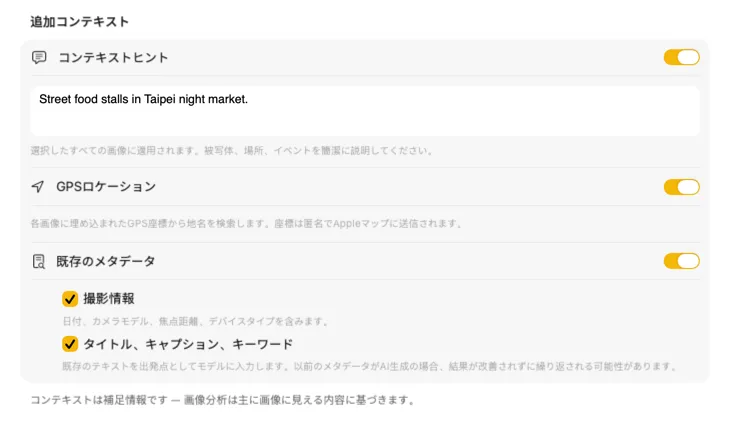
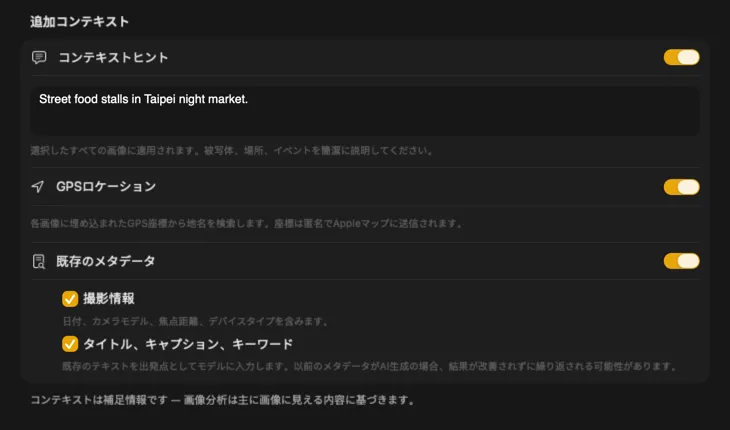
AIに何の写真か伝えると、結果が格段に良くなる。「ヴィンテージ家具店の商品写真」のようなコンテキストヒントを追加したり、GPS Location を有効にして埋め込み座標から地名を取得したり、ファイルに既にあるカメラ情報や編集メタデータを渡したりできる。各ソースはオプションで、プロンプトに直接反映される — AIが推測する必要がなくなる。
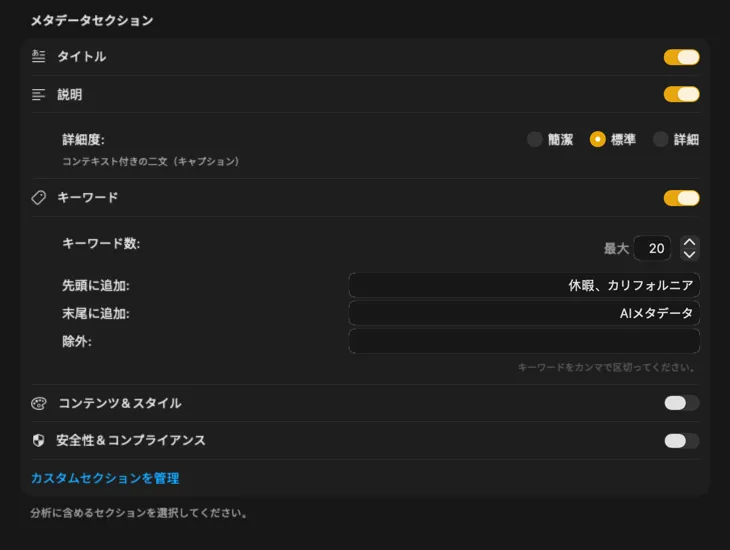
必要なメタデータをピンポイントで生成
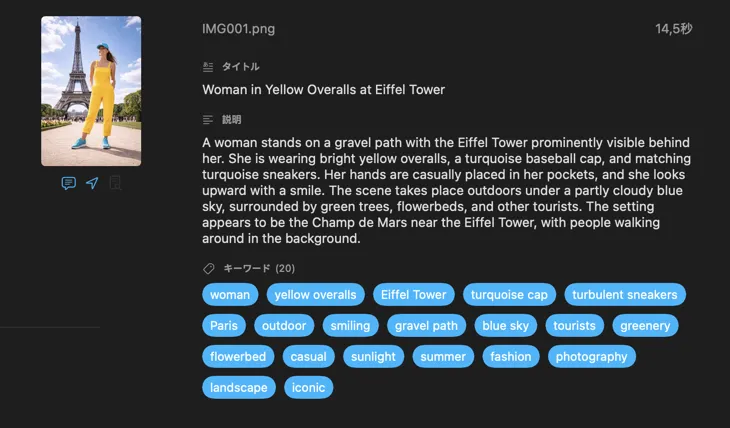
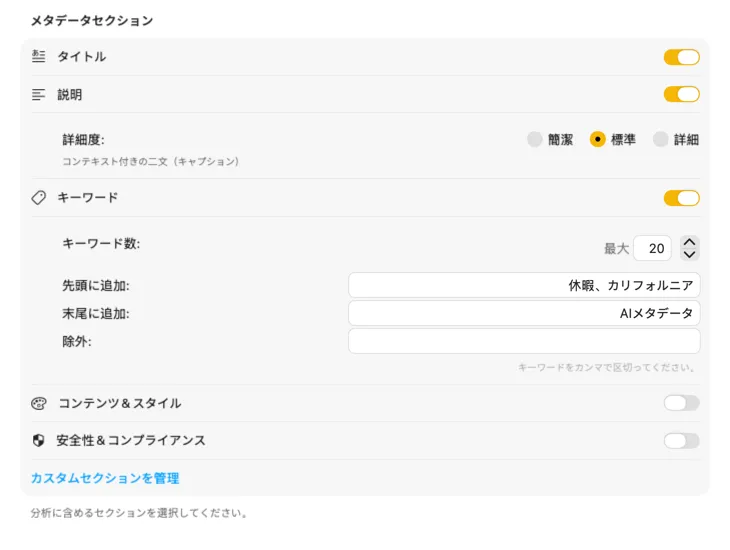
ほとんどの人が必要とするフィールド — タイトル、説明、キーワード — から始めて、さらにコンテンツ&スタイル、安全性&コンプライアンスへ進んだり、自分のフィールドとプロンプトで完全にカスタムなセクションを追加したりできる。他の言語で出力したい?VisionTagger は macOS 内蔵の翻訳機能を使って、生成したメタデータを自動的に翻訳できる。結果は、数千枚の写真にわたる構造化された一貫したメタデータ。
ワークフローにぴったり合う
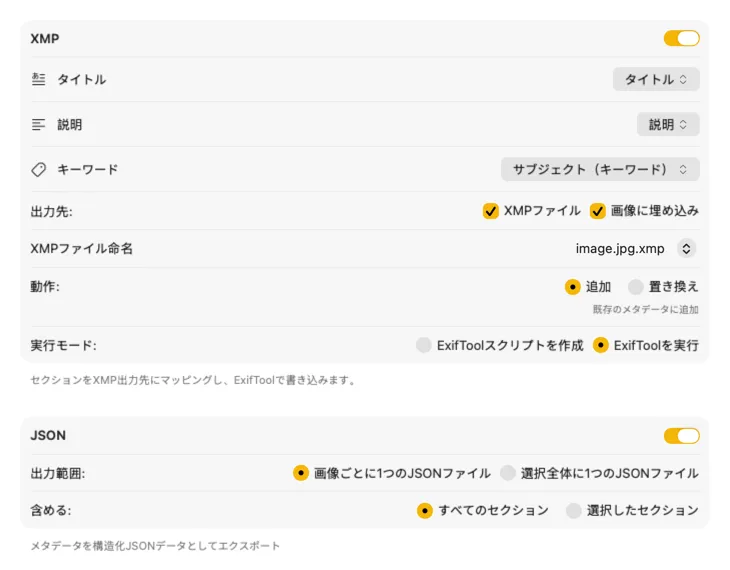
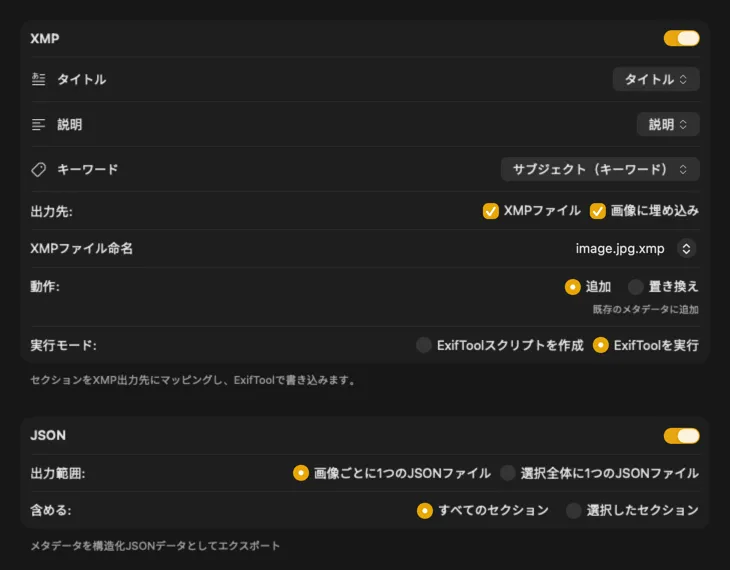
XMP サイドカーや埋め込みメタデータには、VisionTagger は ExifTool と連携する — 業界標準で広く信頼されているユーティリティ。メタデータは Adobe Lightroom、Bridge、Capture One、Photo Mechanic、そしてXMPを読む他のソフトにも表示される。写真ライブラリへの書き戻し、画像ごとの JSON/CSV/TXT 書き出し、または一回の実行分を1ファイルにまとめることもできる。macOS で素早く整理できるように Finder タグも追加可能。複数の出力先を同時に選んでまとめて設定 — 1回の生成で使ってる全部の行き先に流し込める。
自動化して、あとはおまかせ
2つのショートカットアクション — Finder のファイル用と写真ライブラリ用 — で、アプリを開かずにバックグラウンドで全プロセスを実行できる。フォルダの自動化や Finder のクイックアクションを設定したり、コマンドラインから起動したりできる。アプリの現在の設定をそのまま使うか、保存したプリセットを渡して毎回再現性のある結果を。


使い方
YouTubeでデモを見る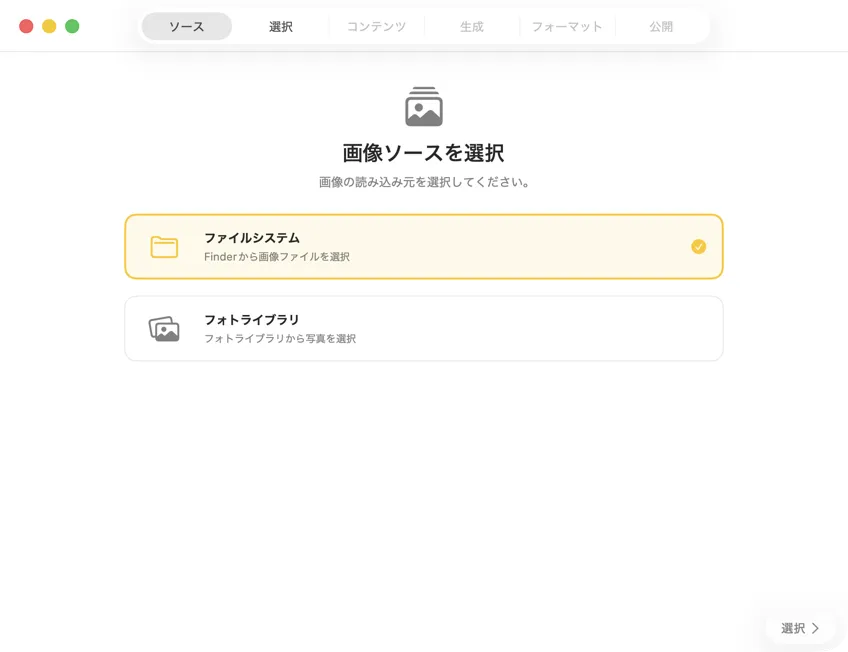
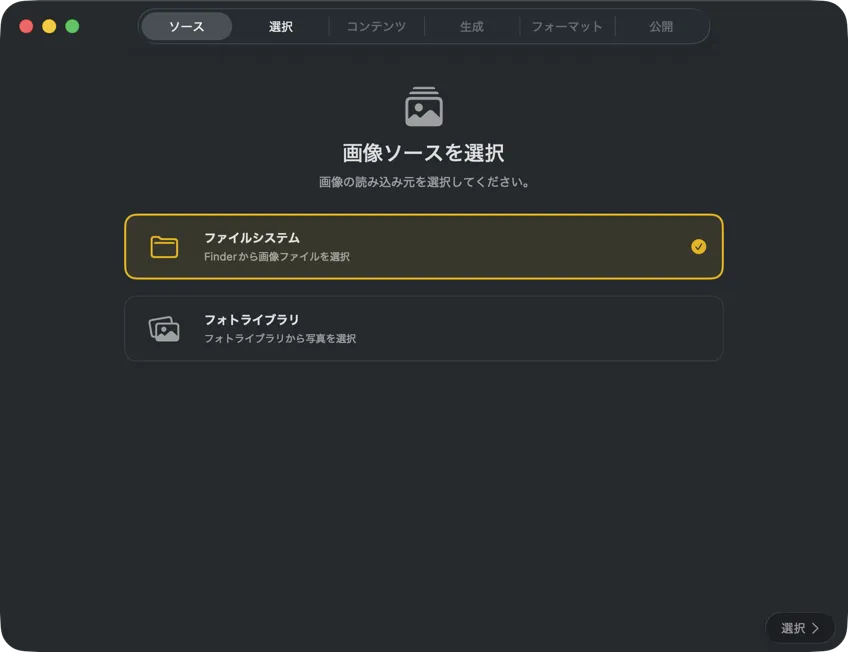
画像がどこにあるか選ぶ — Mac上のフォルダか、写真ライブラリ。
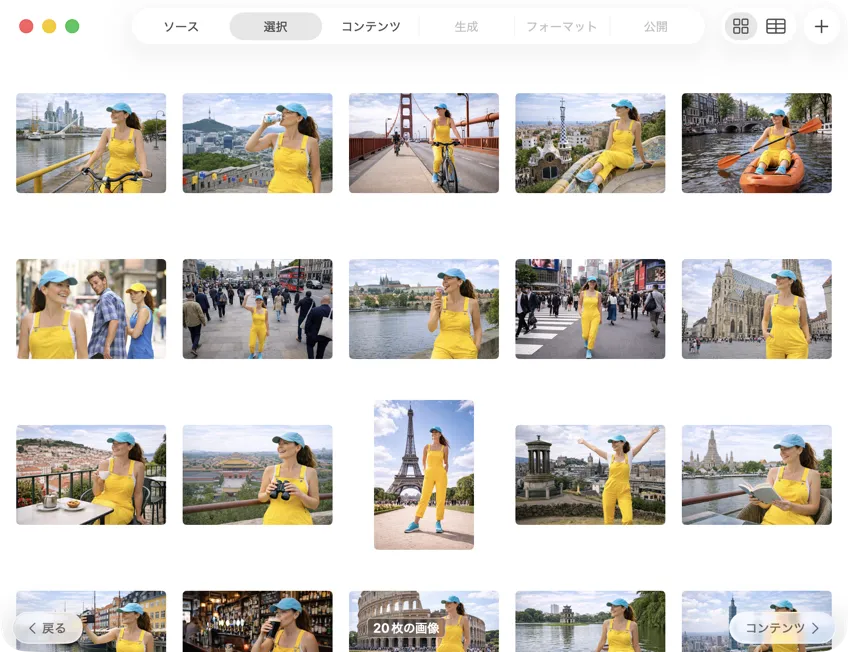
処理したいものだけをきっちり選ぶ。グリッド表示やテーブル表示で確認して、追加ボタンで画像を足したり、ファイルをアプリにドラッグ&ドロップしてバッチを作れる。
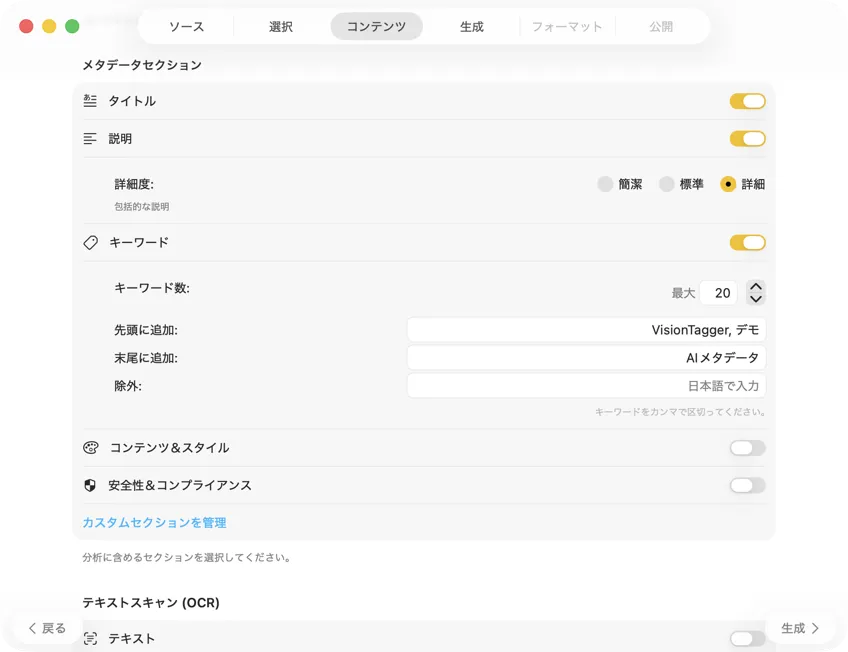
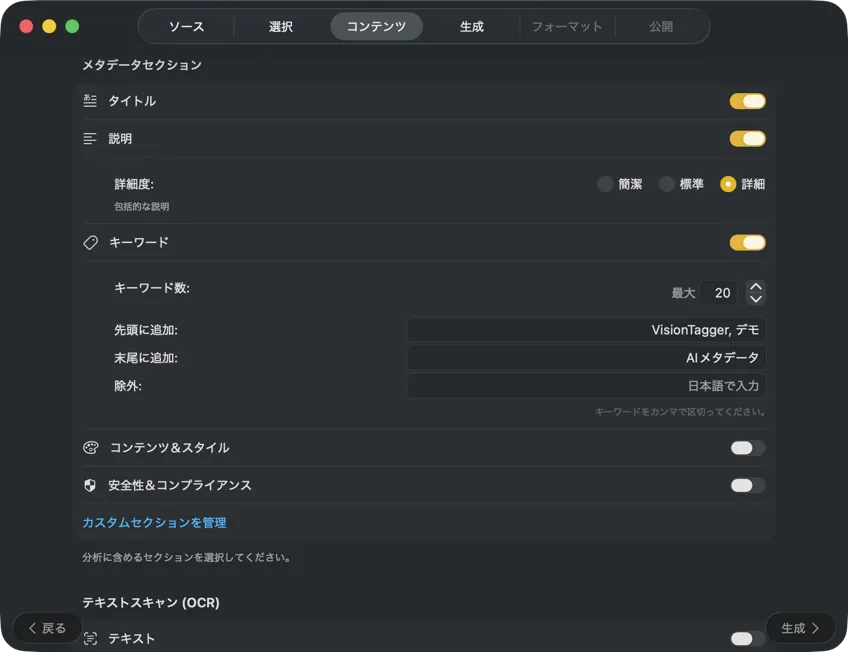
AIモデルを選んで(アプリ内でワンクリックでダウンロード)、生成したいメタデータを決める:タイトル、説明、キーワード、スタイルタグ、安全性評価、または自分のカスタムフィールド。
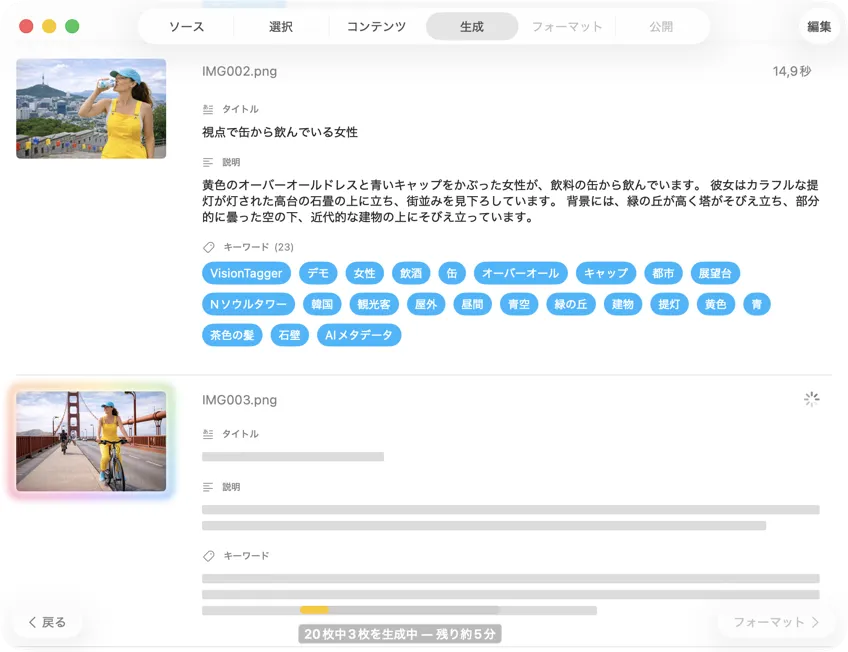
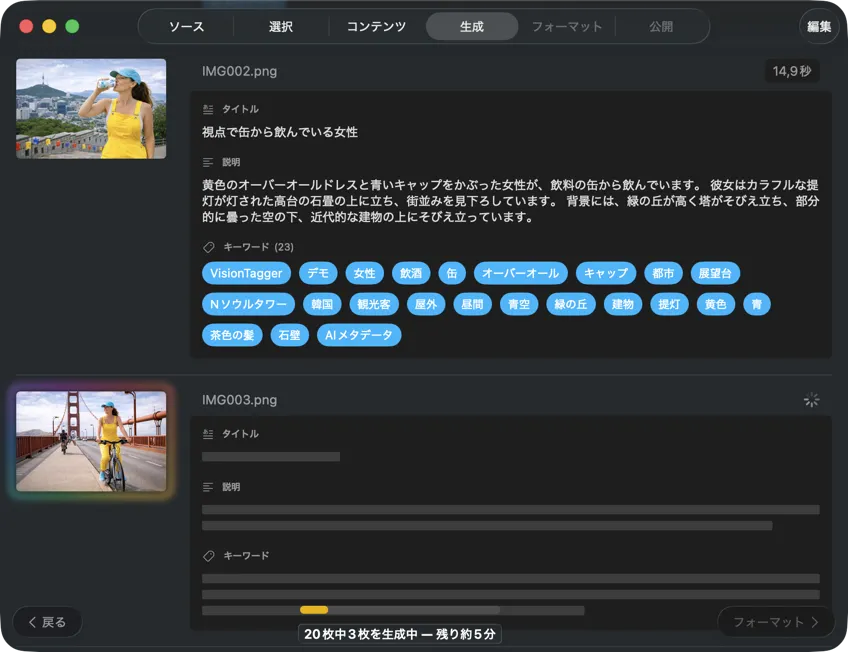
結果がリアルタイムで出てくるのを見られる。VisionTagger は画像をローカルで処理して、各アイテムの準備ができ次第、生成メタデータをスクロールするリストに流し込むから、バッチが続いてる間に出力を確認して編集できる。
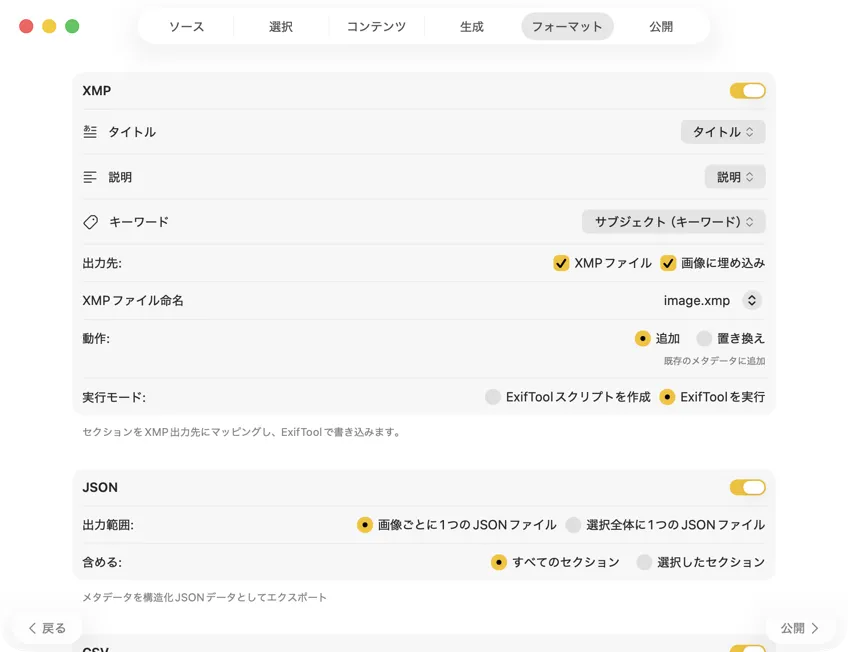
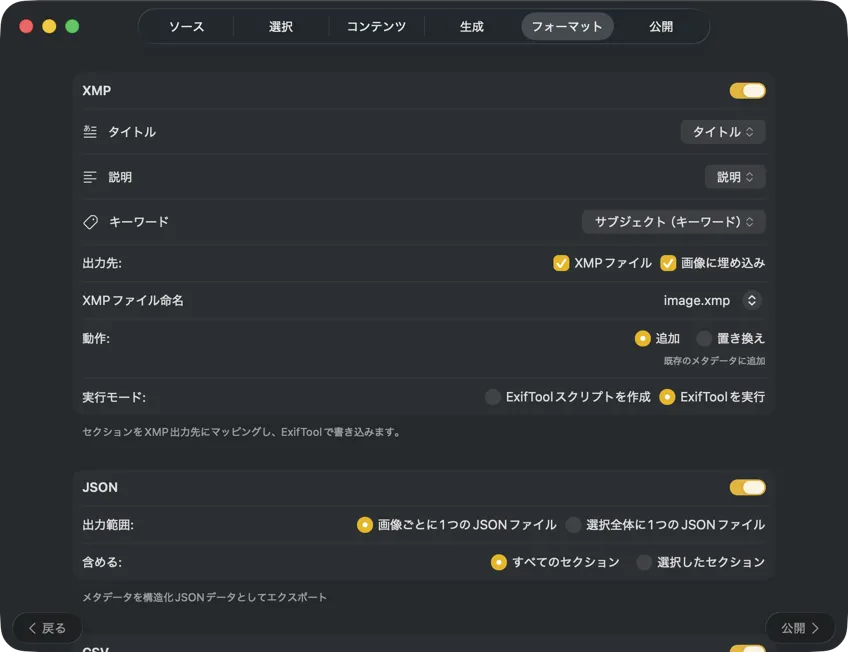
メタデータの行き先を選ぶ:フォトカタログ向けの XMP サイドカー、Webパイプライン向けの JSON や CSV、Finder タグ、または写真ライブラリへの書き戻し。複数の出力を同時に選択できる。
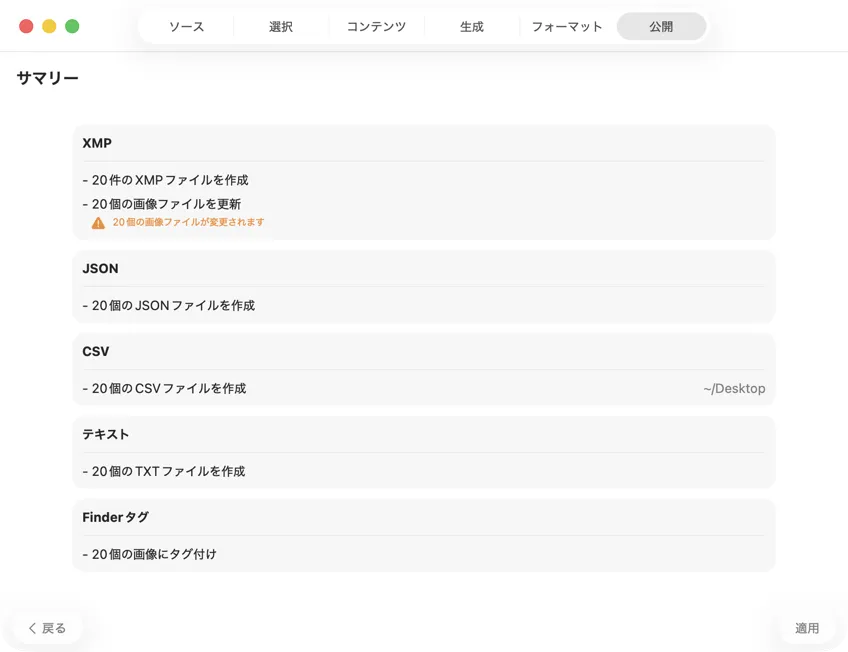
書き込む前に必ず確認。実行される全アクションの分かりやすいサマリーを確認して、既存のファイルやメタデータが上書きされる可能性があるときは警告も出る — その上で公開して、選んだ出力を安心して適用できる。
買い切り
VAT込み
FastSpring による安全な決済