Fotos nie wieder manuell taggen.
VisionTagger nutzt On-Device-KI, um Titel, Beschreibungen, Keywords und mehr für deine Bilder zu erzeugen — in Batches, ohne Uploads und ohne Kosten pro Bild.
Benötigt einen Apple Silicon-Mac mit macOS 26

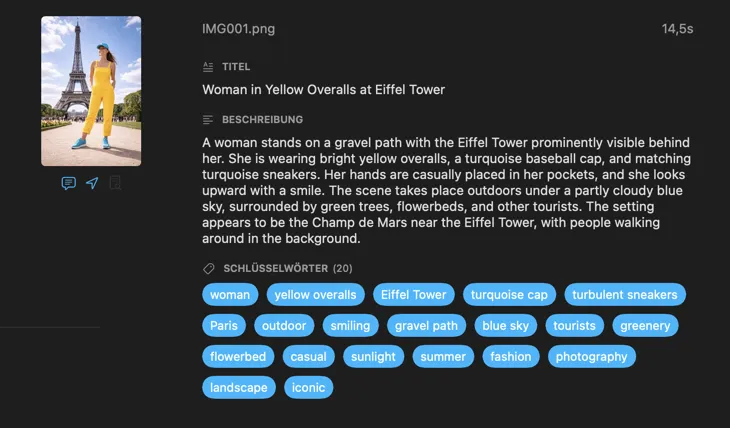
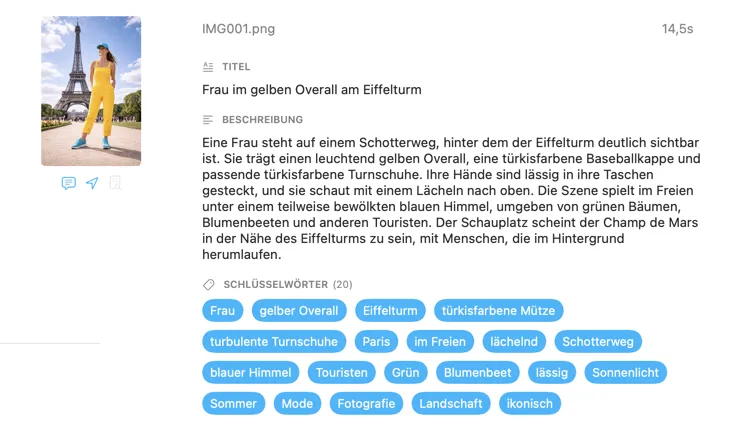
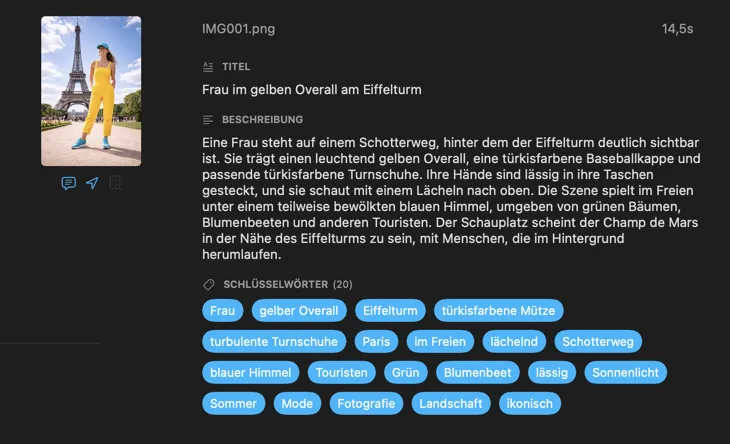
Für wen ist VisionTagger?
-
Designer*innen, die in Projektdateien suchen — tagge Bilder nach Stimmung, Stil, Motiv und Verwendung, um deine Asset-Bibliothek sofort durchsuchbar zu machen.
-
Forscher*innen und Archivar*innen, die Sammlungen bewahren — erstelle strukturierte, konsistente Metadaten für Datensätze, Aufzeichnungen und langfristige digitale Archivierung.
Bessere Ergebnisse mit Kontext, den du schon hast
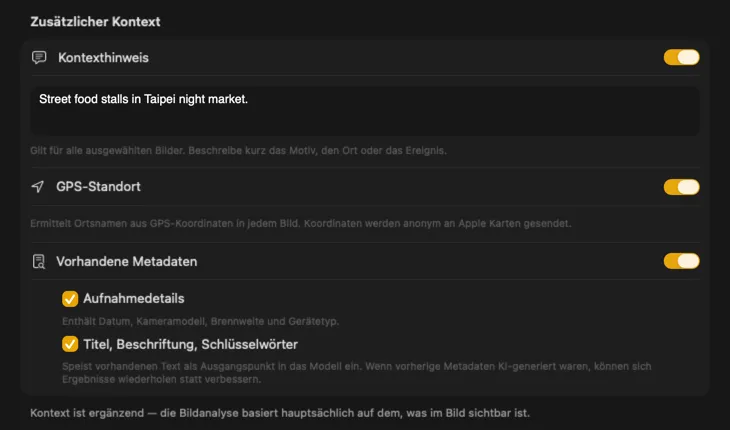
Sag der KI, was sie vor sich hat, und die Ergebnisse werden deutlich besser. Füge einen Kontexthinweis hinzu wie “Produktfotos für einen Vintage-Möbelladen”, aktiviere GPS-Standort, um Ortsnamen aus eingebetteten Koordinaten nachzuschlagen, oder übergib Kamera- und redaktionelle Metadaten, die schon in deinen Dateien stecken. Jede Quelle ist optional und fließt direkt in den Prompt ein — damit die KI nicht raten muss.
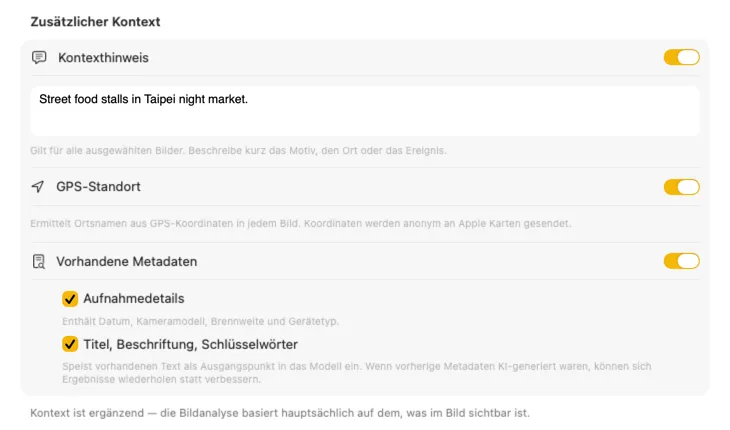
Erzeuge genau die Metadaten, die du brauchst
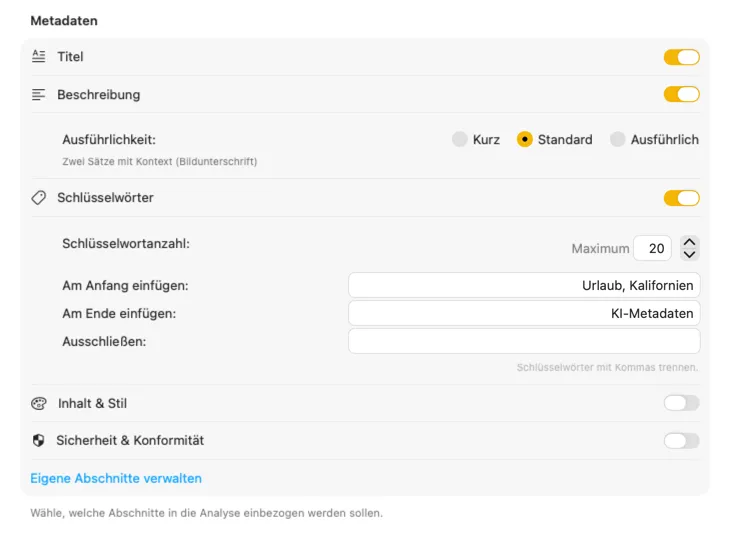
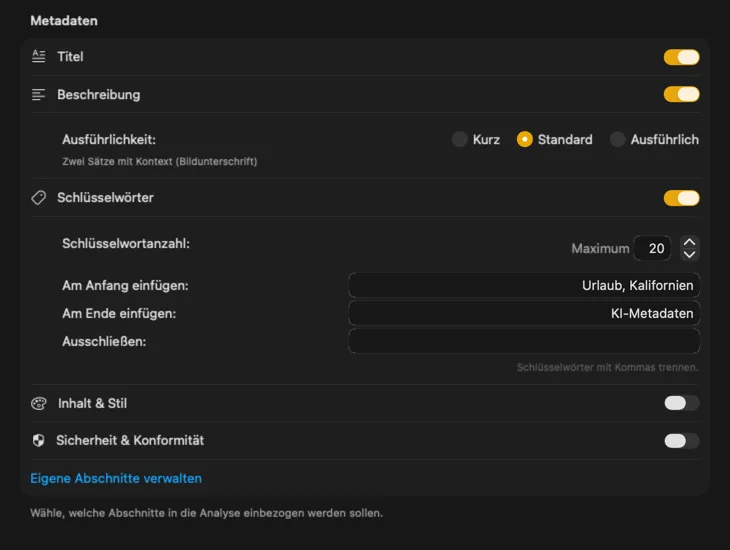
Starte mit den Feldern, die die meisten brauchen — Titel, Beschreibung und Keywords — und geh dann weiter mit Inhalt & Stil, Sicherheit & Compliance oder füge komplett eigene Sektionen mit deinen Feldern und Prompts hinzu. Brauchst du die Ausgabe in einer anderen Sprache? VisionTagger kann generierte Metadaten automatisch mit der in macOS integrierten Übersetzung übersetzen. Das Ergebnis sind strukturierte, konsistente Metadaten über Tausende von Fotos.
Passt nahtlos in deinen Workflow
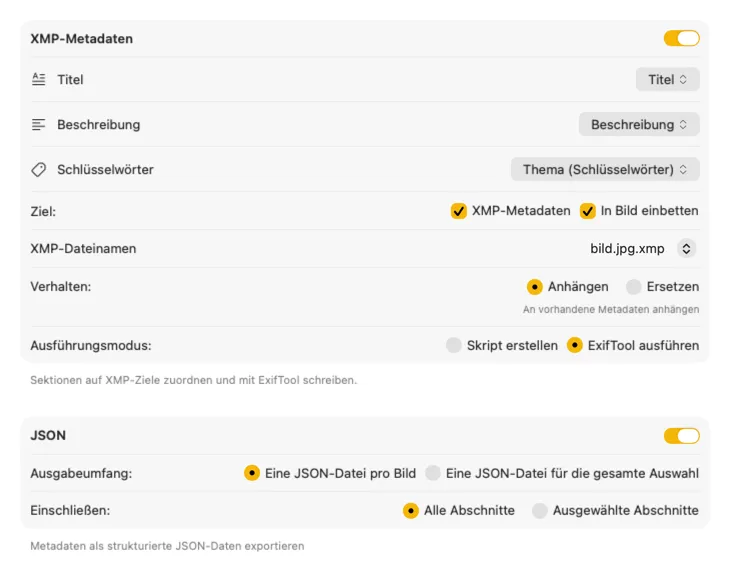
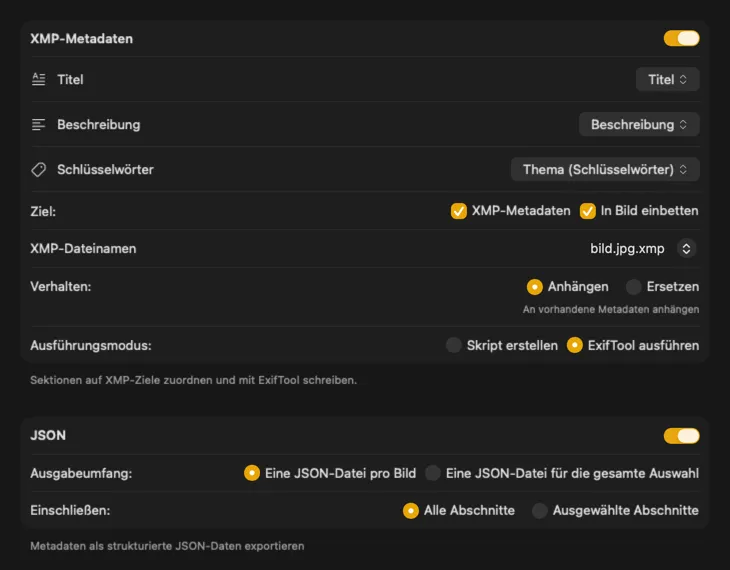
Für XMP-Sidecars und eingebettete Metadaten integriert sich VisionTagger mit ExifTool — einem Branchenstandard und weithin vertrauenswürdigen Tool. Deine Metadaten erscheinen in Apps wie Adobe Lightroom, Bridge, Capture One, Photo Mechanic und jeder anderen Software, die XMP liest. Schreib zurück in deine Fotos-Mediathek, exportiere JSON, CSV oder TXT pro Bild oder erzeuge eine einzelne Datei für einen kompletten Run. Füge Finder-Tags für schnelle Organisation in macOS hinzu. Wähle mehrere Ausgaben gleichzeitig und konfiguriere sie zusammen — damit ein Generierungslauf jedes Ziel versorgt, das du nutzt.
Automatisiere es und vergiss es
Zwei Kurzbefehle-Aktionen — eine für Dateien im Finder, eine für deine Fotos-Mediathek — lassen dich den kompletten Prozess im Hintergrund ausführen, ohne die App zu öffnen. Richte eine Ordnerautomatisierung ein, eine Finder-Schnellaktion, oder starte es über die Kommandozeile. Nutze die aktuellen Einstellungen der App oder liefere ein gespeichertes Preset für jedes Mal reproduzierbare Ergebnisse.


So funktioniert’s
Demo auf YouTube ansehen
Wähle, wo deine Bilder liegen — Ordner auf deinem Mac oder deine Fotos-Mediathek.
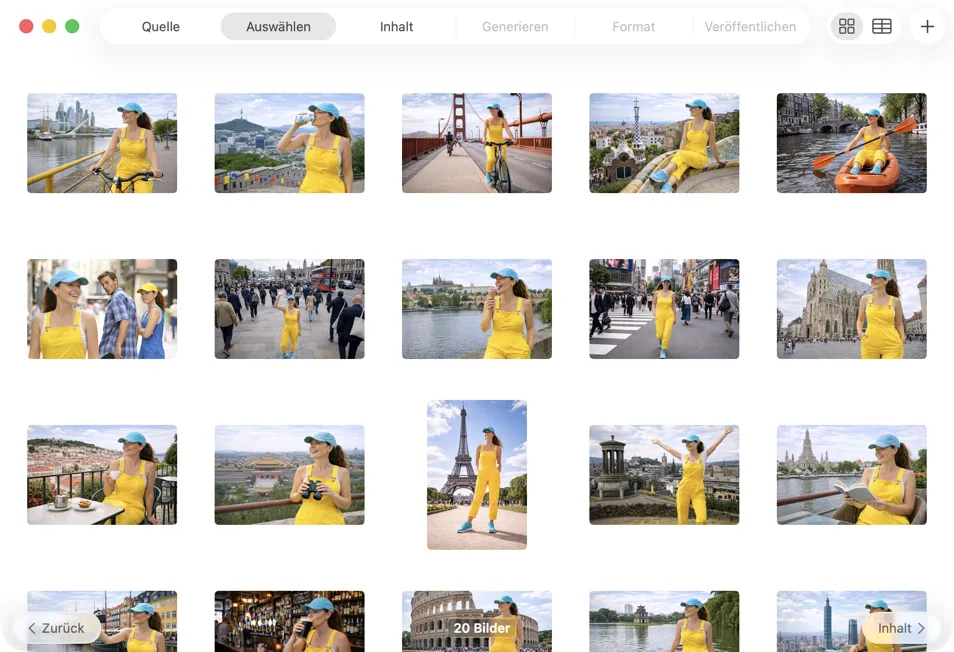
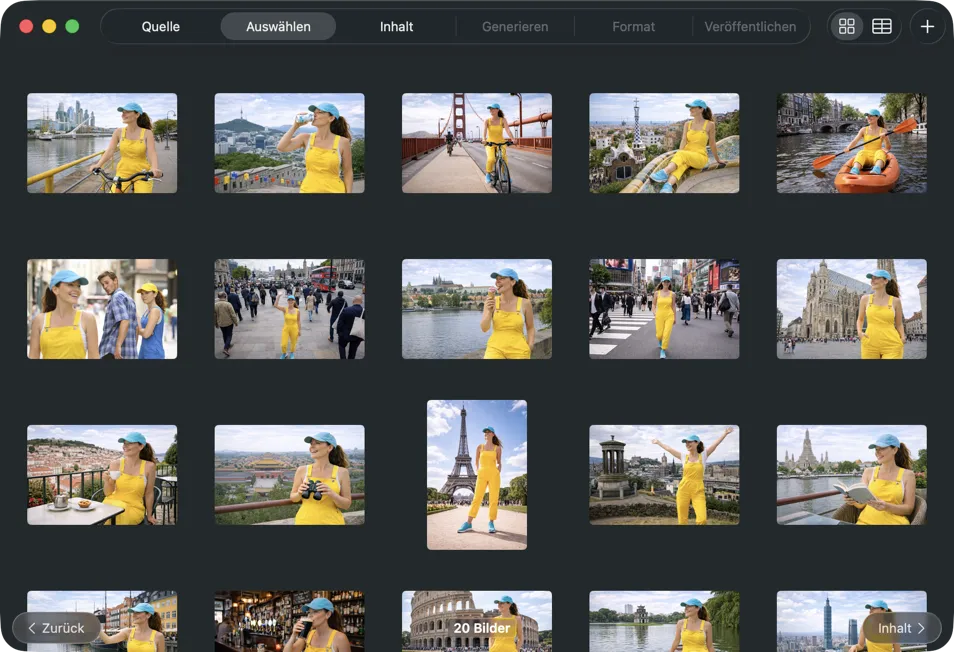
Wähle genau aus, was du verarbeiten willst. Schau dir deine Auswahl in einer Raster- oder Tabellenansicht an, füge über den Hinzufügen-Button weitere Bilder hinzu oder zieh Dateien per Drag & Drop in die App, um einen Batch zu bauen.
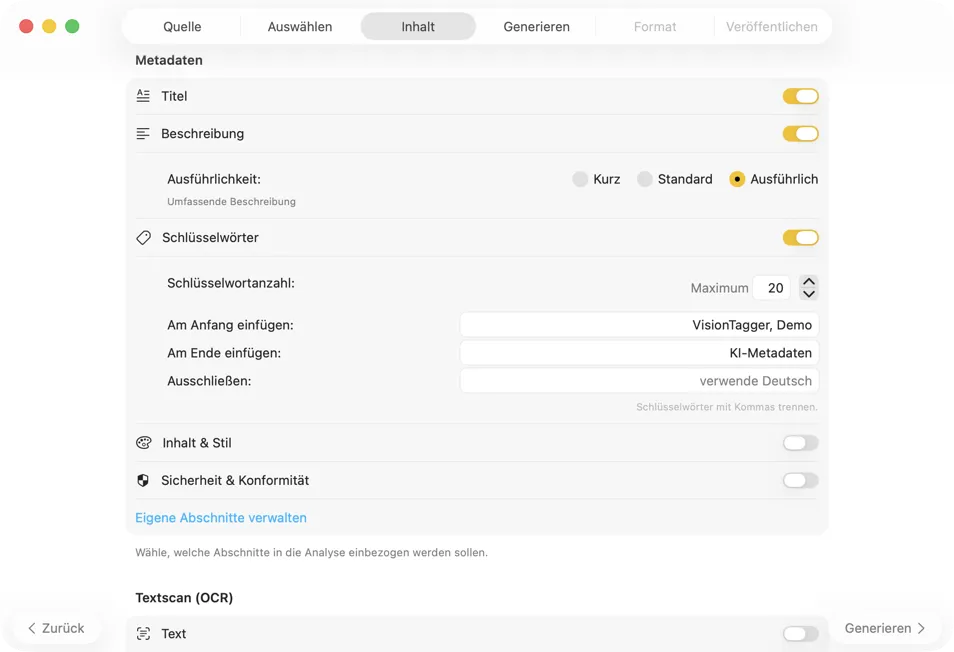
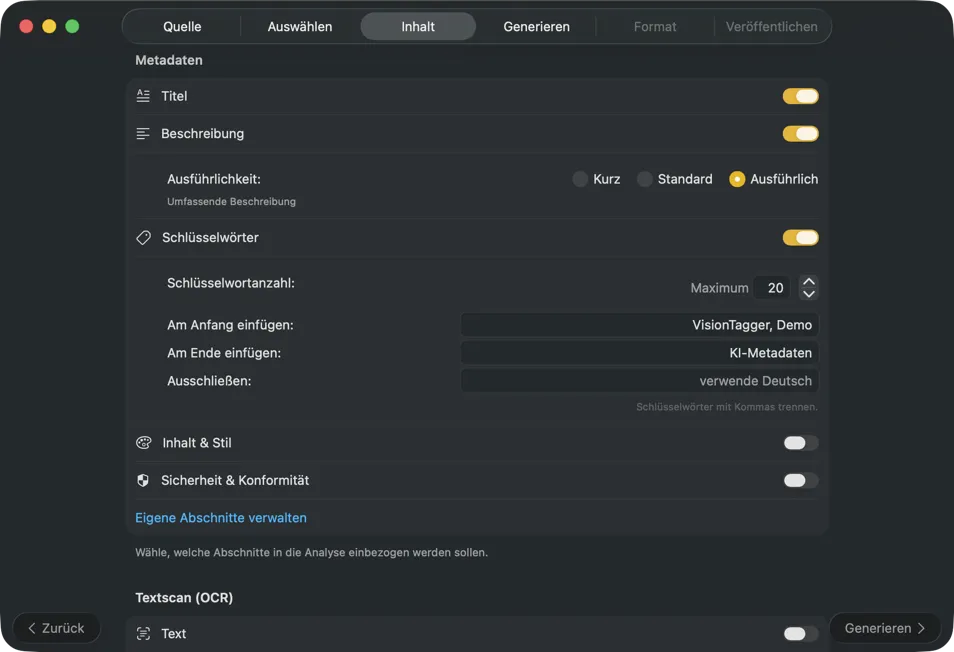
Wähle ein KI-Modell (lade eines in der App mit einem Klick herunter) und bestimme, welche Metadaten du erzeugen willst: Titel, Beschreibungen, Keywords, Stil-Tags, Sicherheitsbewertungen oder deine eigenen Custom-Felder.
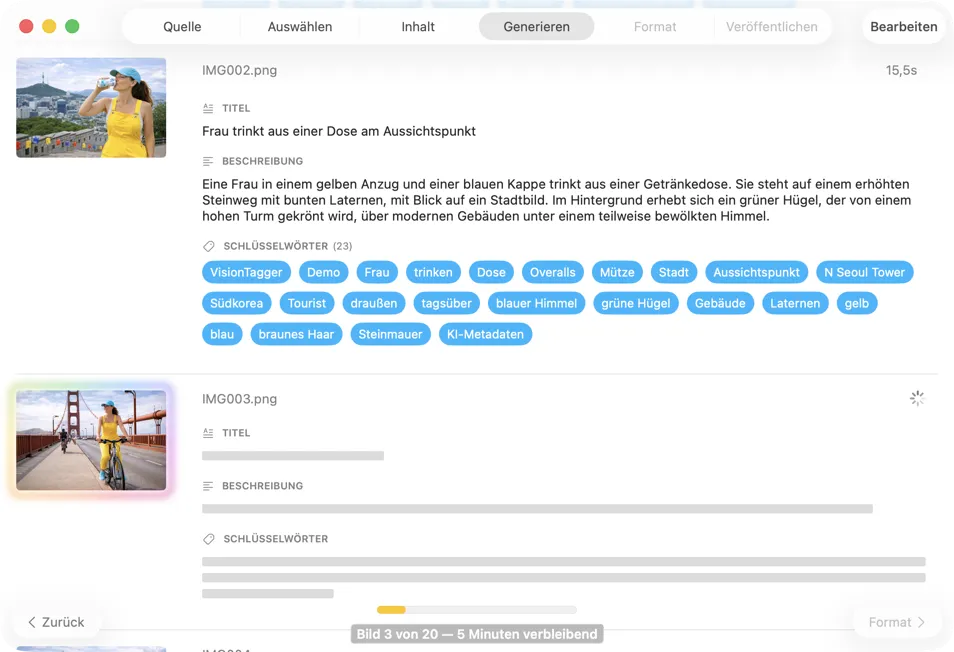
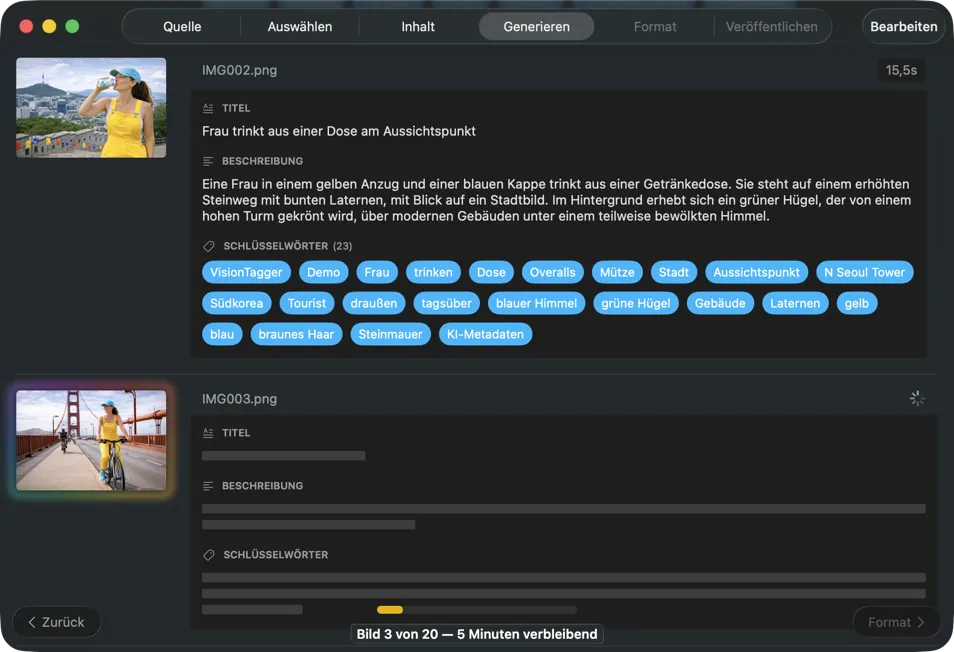
Sieh zu, wie Ergebnisse in Echtzeit auftauchen. VisionTagger verarbeitet Bilder lokal und streamt erzeugte Metadaten sofort nach Fertigstellung jedes Elements in eine scrollende Liste, sodass du Ausgaben prüfen und bearbeiten kannst, während der Batch weiterläuft.
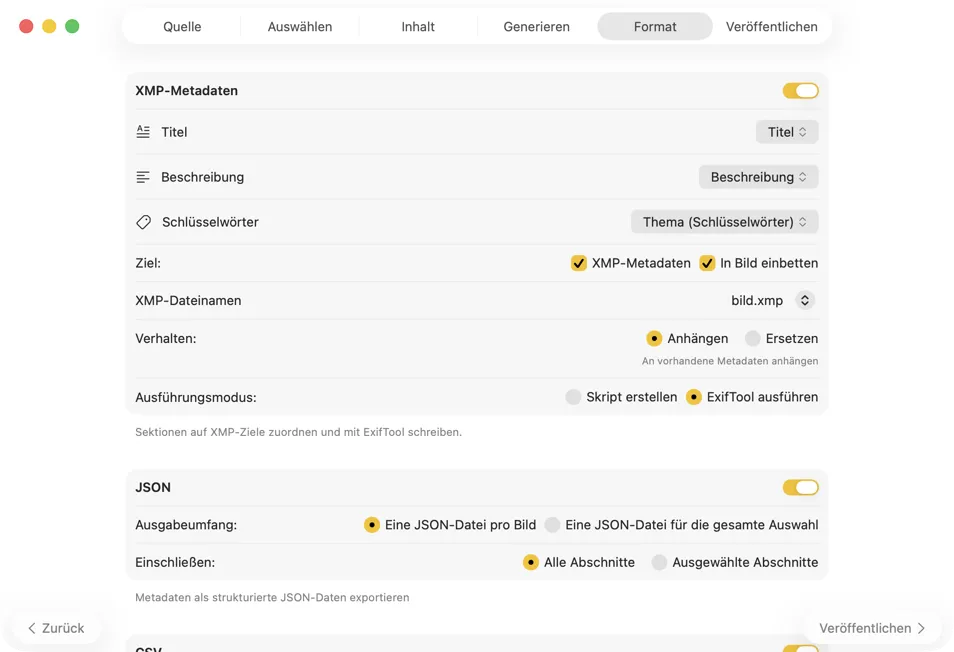
Wähle, wohin die Metadaten gehen: XMP-Sidecars für deinen Fotokatalog, JSON oder CSV für deine Website-Pipeline, Finder-Tags oder schreibe zurück in Fotos. Wähle mehrere Ausgaben gleichzeitig.
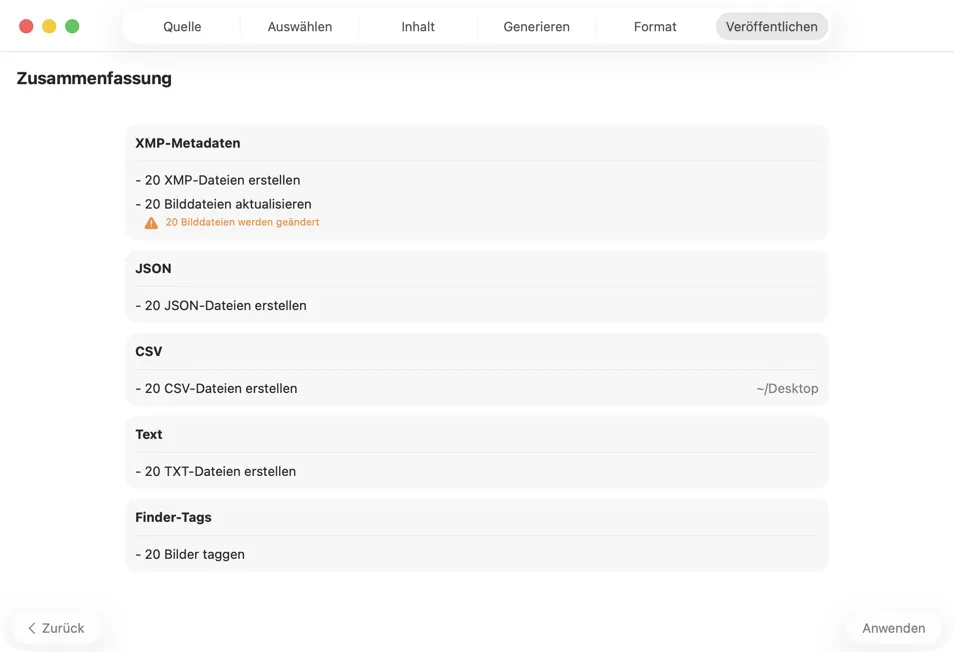
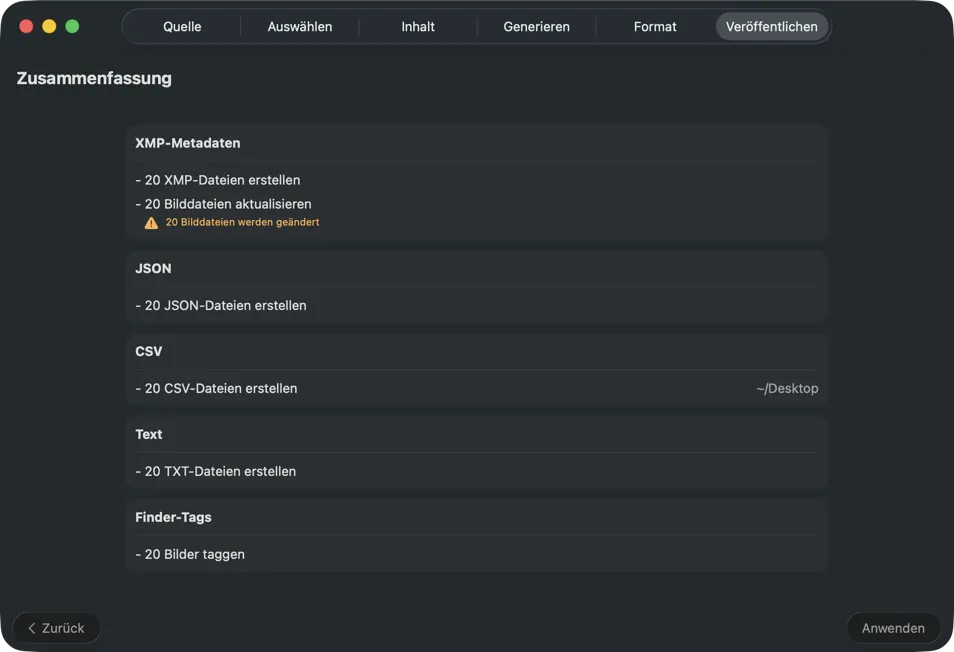
Bestätige, bevor irgendetwas geschrieben wird. Sieh dir eine klare Zusammenfassung aller Aktionen an, die ausgeführt werden — inklusive Warnungen, wenn vorhandene Dateien oder Metadaten überschrieben werden könnten — und veröffentliche dann, um deine ausgewählten Ausgaben mit Vertrauen anzuwenden.
Einmalkauf
MwSt. inklusive
Sichere Zahlung über FastSpring