Genereer afbeeldingsmetadata. Lokaal.
Maak rijke, gestructureerde metadata van afbeeldingen met lokale vision-modellen — zonder uploads, abonnementen of dat je gegevens je Mac verlaten.
Vereist Apple Silicon Mac met macOS 26
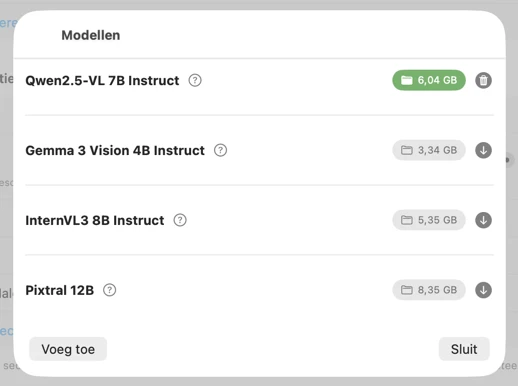
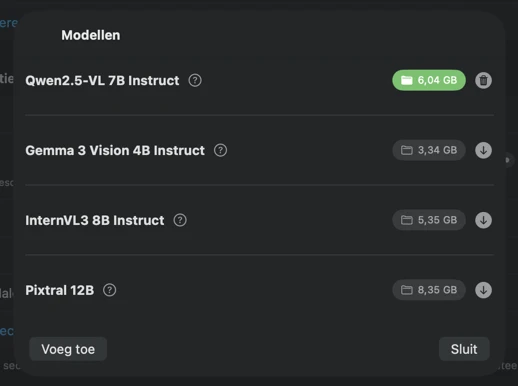
Kies een model — of gebruik je eigen model
Download vooraf geconfigureerde vision-modellen in de app, of koppel je eigen GGUF-model en projectorbestanden. Kies het model dat het beste past bij je afbeeldingen en kwaliteitseisen, en finetune vervolgens de generatie met instelbare parameters om consistente, herhaalbare resultaten te krijgen. Alle verwerking draait lokaal op Apple Silicon (M1 of later), waarbij je de rekenkracht van je Mac gebruikt in plaats van een cloudservice.
Definieer je eigen metadataschema
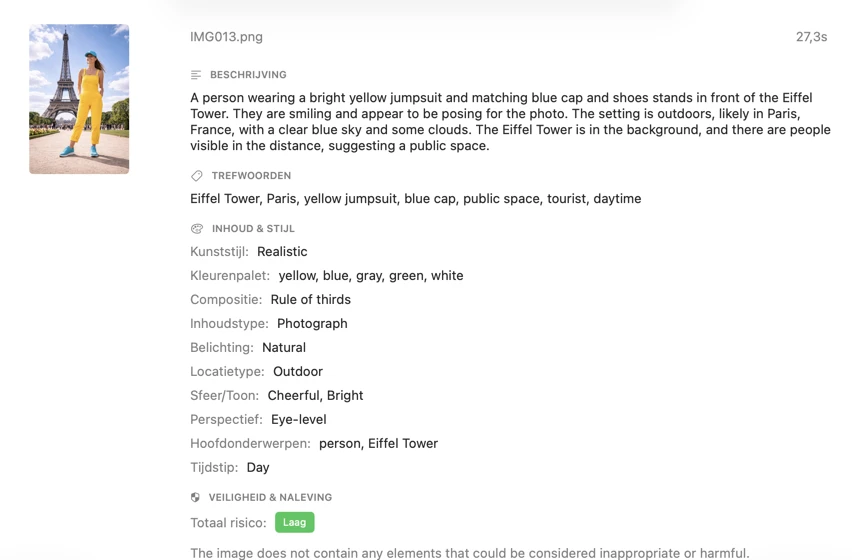
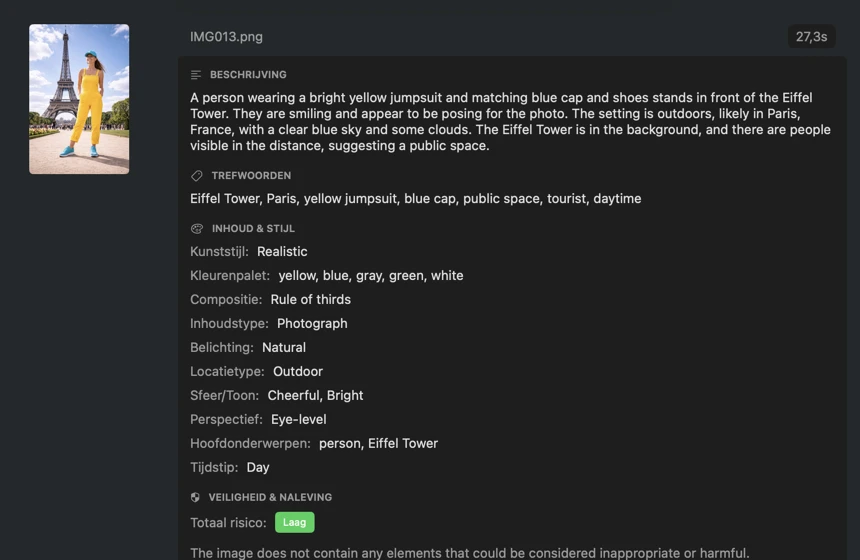
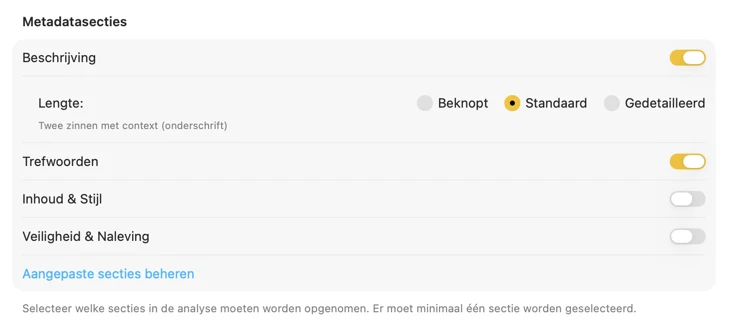
Genereer alleen de metadata die je echt nodig hebt. Schakel ingebouwde secties in zoals Titel, Beschrijving, Trefwoorden, Inhoud & Stijl en Veiligheid & Compliance — en breid ze vervolgens uit met aangepaste secties en velden die zijn afgestemd op je workflow. Kies per veld een gegevenstype (Boolean, Tekst of Lijst met teksten) en schrijf een prompt die het model precies vertelt wat het moet extraheren. Het resultaat is gestructureerde metadata die aansluit op je conventies en consistent blijft, ook bij grote batches.
Exporteer metadata waar je het nodig hebt
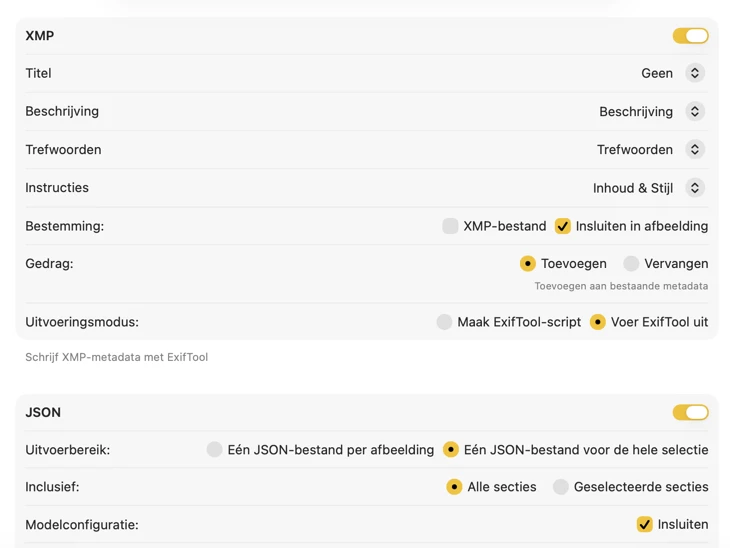
Publiceer metadata in het formaat dat het beste past bij je workflow. Voor XMP-sidecars en embedded metadata integreert VisionTagger met ExifTool — een industriestandaard en breed vertrouwde tool. Je metadata verschijnt in apps zoals Adobe Lightroom, Bridge, Capture One, Photo Mechanic en alle andere software die XMP leest. Schrijf terug naar je Foto's-bibliotheek, exporteer JSON, CSV of TXT per afbeelding, of genereer één bestand voor een volledige run. Voeg Finder-tags toe voor snelle organisatie in macOS. Selecteer meerdere outputs tegelijk en configureer ze samen — zodat één generatiepass elke bestemming kan vullen die je gebruikt.
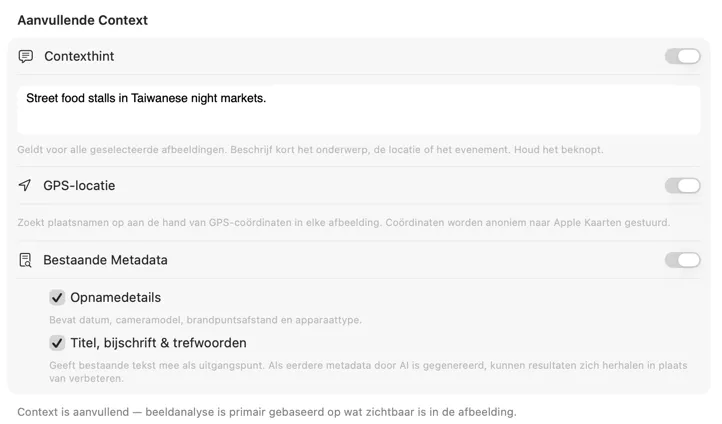
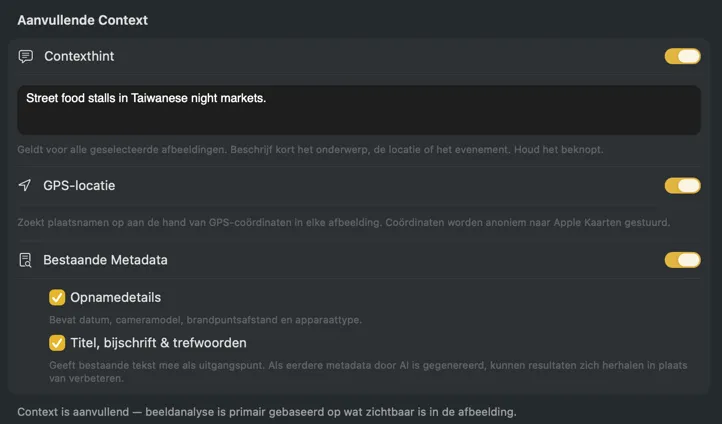
Voeg context toe voor slimmere resultaten
Geef het model meer om mee te werken. Voeg een vrije-tekst Contexthint toe om je batch te beschrijven — zoals "productfoto's voor een vintage meubelwinkel" — schakel GPS-locatie in om plaatsnamen op te zoeken via Apple Kaarten aan de hand van ingebedde coördinaten, of geef Bestaande Metadata mee zoals opnamedetails en redactionele velden die al in je bestanden staan. Elke bron is optioneel, werkt onafhankelijk en wordt direct in de prompt opgenomen voor nauwkeurigere, locatiebewuste resultaten.
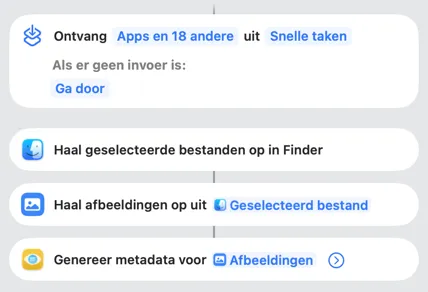
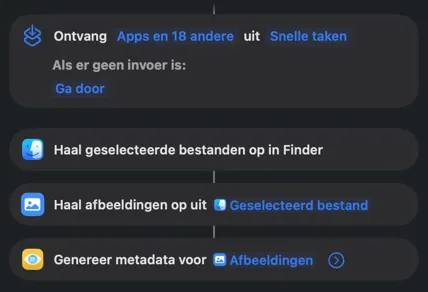
Automatiseer met Opdrachten
Draai de volledige verwerkingspipeline van VisionTagger zonder de app te openen. Twee speciale Opdrachten-acties — Genereer afbeeldingsmetadata voor bestanden in Finder en Genereer fotometadata voor je Foto's-bibliotheek — laten je metadata genereren en exporteren zonder interface. Gebruik de huidige instellingen van de app of lever een op zichzelf staande instellingenpreset aan voor herhaalbare resultaten. De acties werken overal waar Opdrachten werkt: de Opdrachten-app, Finder-snelacties, mapautomatiseringen, de opdrachtregel en AppleScript.
Toepassingen
-
Designers die asset-bibliotheken organiseren — maak stemming, stijl, onderwerp en gebruik eenvoudiger doorzoekbaar over projecten heen.
-
Onderzoekers en archivarissen die collecties labelen — maak gestructureerde, consistente metadata voor datasets, archiefstukken en langdurige bewaring.
Systeemvereisten
-
macOS Tahoe 26.0 of nieuwer
-
Apple Silicon vereist (M1 of nieuwer)
-
Voor een optimale performance met grotere modellen is 16GB RAM of meer aanbevolen
-
Modelopslag: reken op ~4–8 GB per model (lokaal gedownload)
Van afbeeldingen naar metadata — in zes stappen
Bekijk demo op YouTube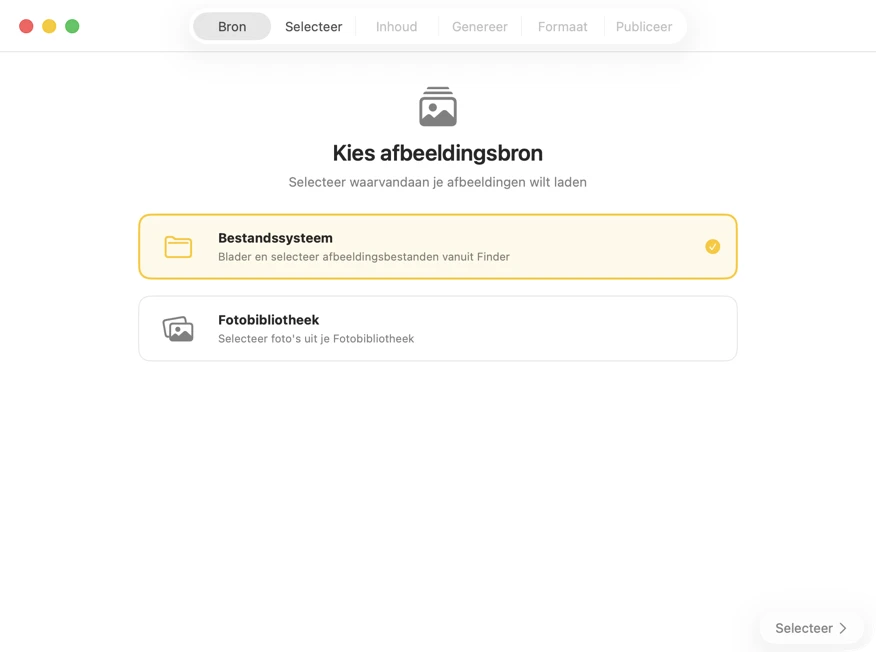
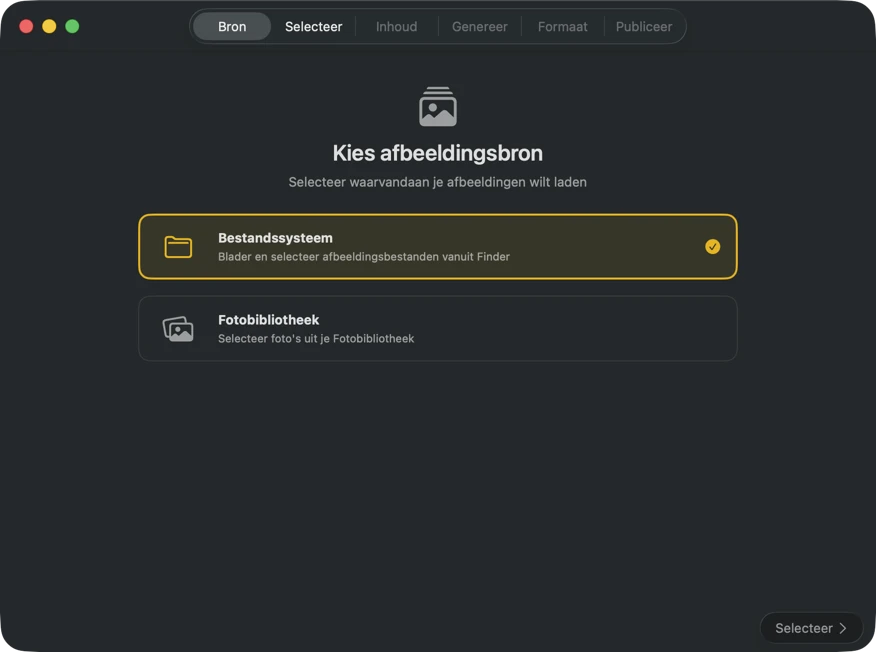
Kies waar je afbeeldingen zijn opgeslagen — mappen op je Mac of je Foto’s-bibliotheek.
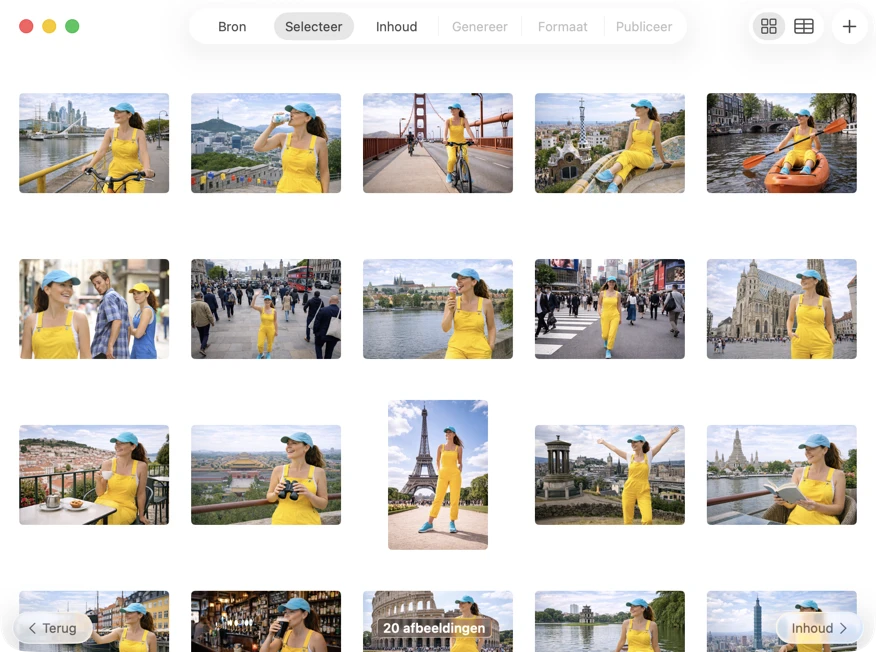
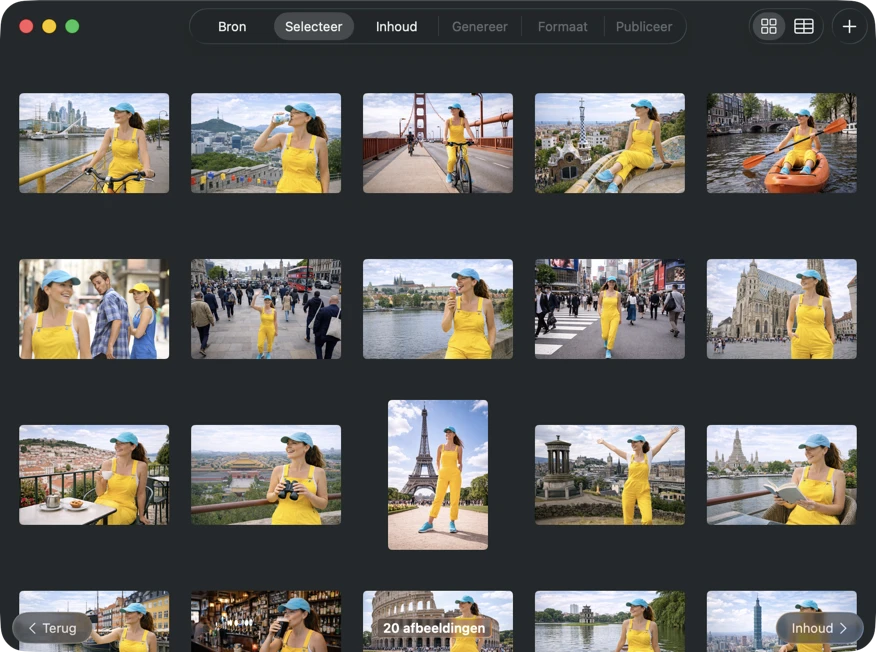
Kies precies wat je wilt verwerken. Bekijk je selectie in raster- of tabelweergave, voeg extra afbeeldingen toe via de toevoegen-knop of sleep bestanden naar de app om een batch samen te stellen.
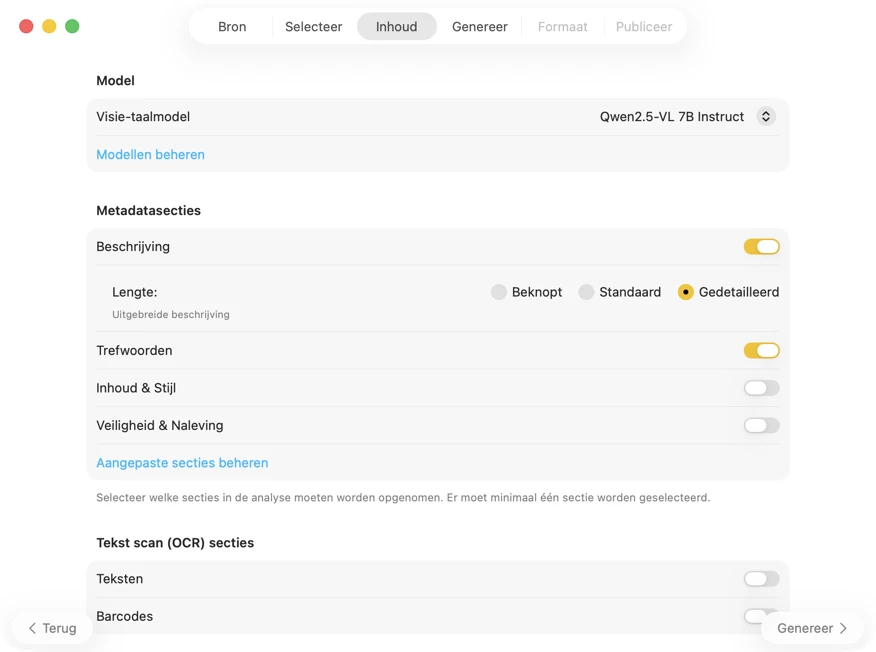
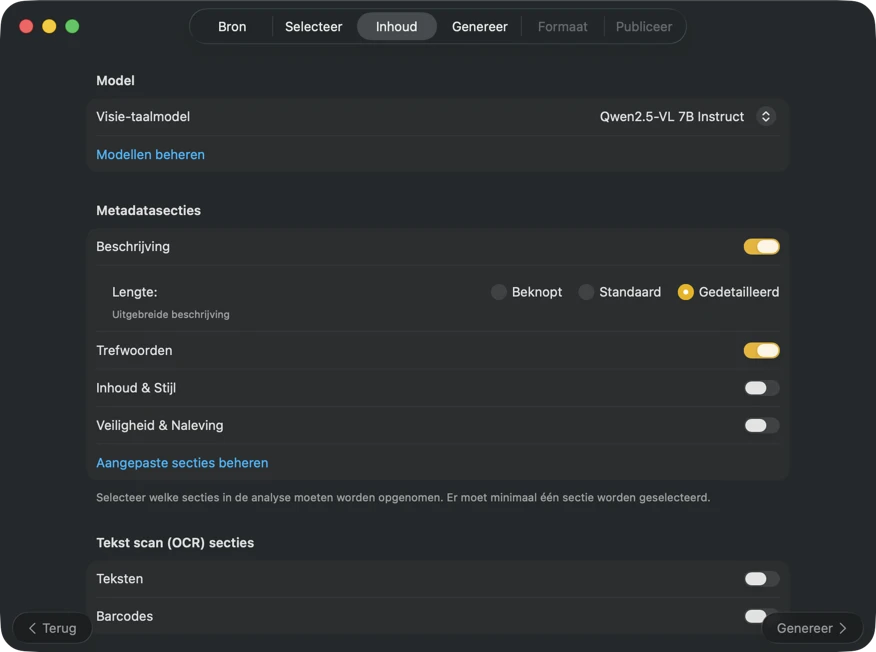
Kies hoe metadata wordt gegenereerd. Download een van de vooraf geconfigureerde vision-modellen, of koppel je eigen GGUF-model + projectorbestanden. Selecteer vervolgens de metadatasecties die je wilt (Titel, Beschrijving, Trefwoorden, Inhoud & Stijl, Veiligheid & Compliance) en voeg eventueel aangepaste secties toe met je eigen velden, gegevenstypen en prompts voor volledig afgestemde output.
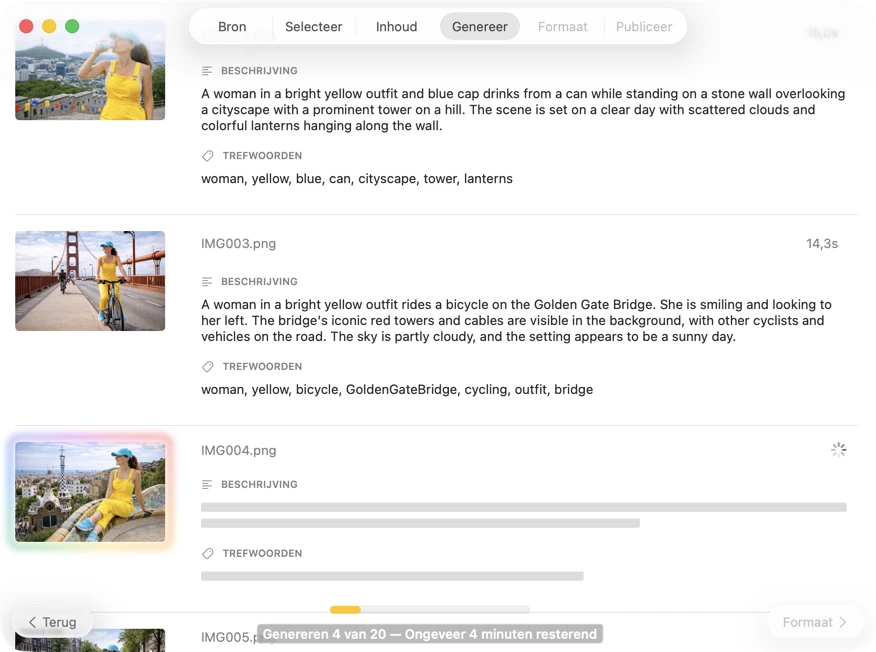
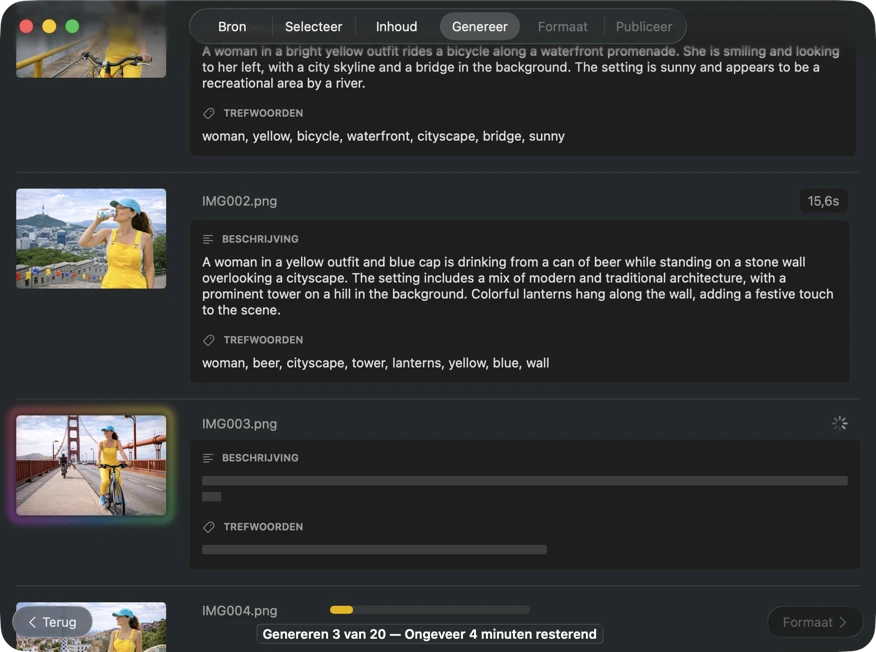
Zie resultaten in realtime verschijnen. VisionTagger verwerkt afbeeldingen lokaal en streamt gegenereerde metadata naar een scrollende lijst zodra elk item klaar is, zodat je outputs kunt beoordelen en bijwerken terwijl de batch doorgaat.
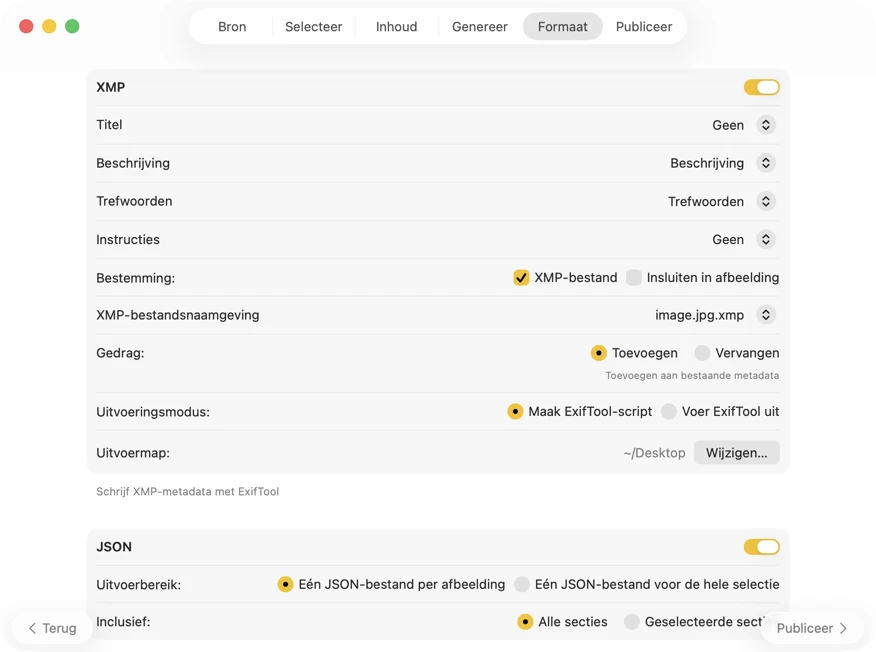
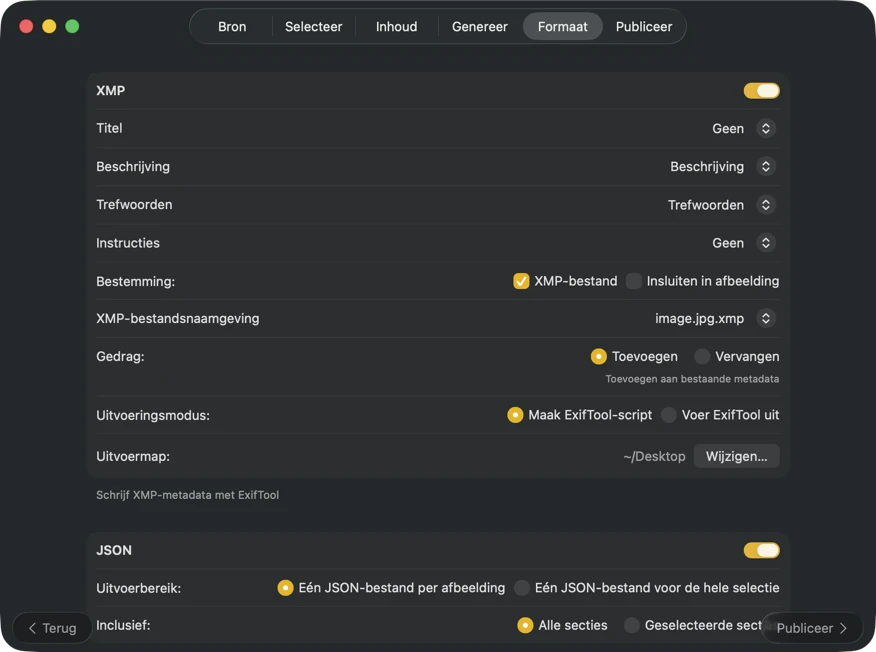
Bepaal waar de metadata naartoe moet. Exporteer per afbeelding of per batch (JSON, CSV of TXT), pas Finder-tags toe en configureer meerdere outputs tegelijk. Voor XMP-sidecars en embedded metadata gebruikt VisionTagger ExifTool (apart te installeren) voor betrouwbare, breed compatibele resultaten.
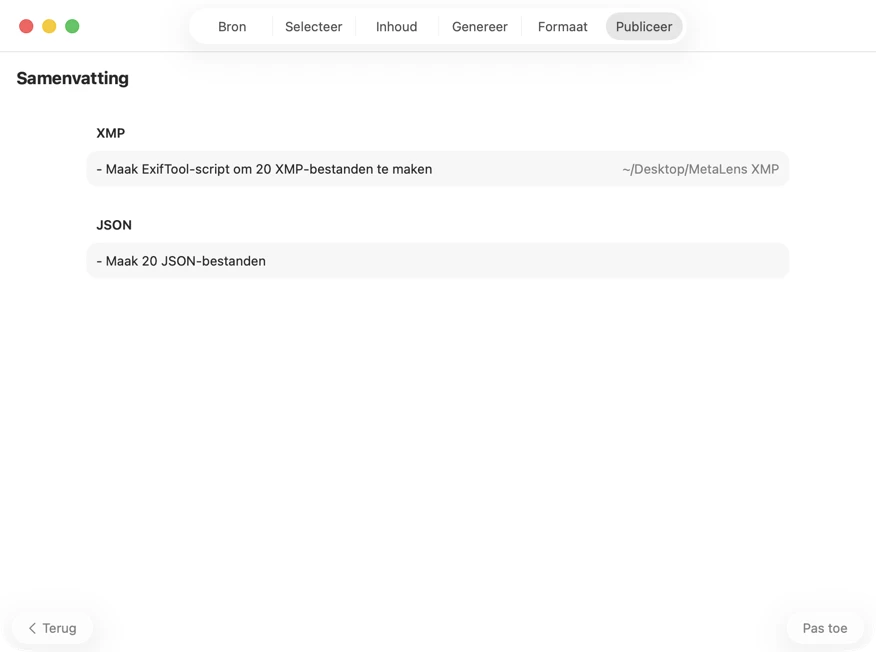
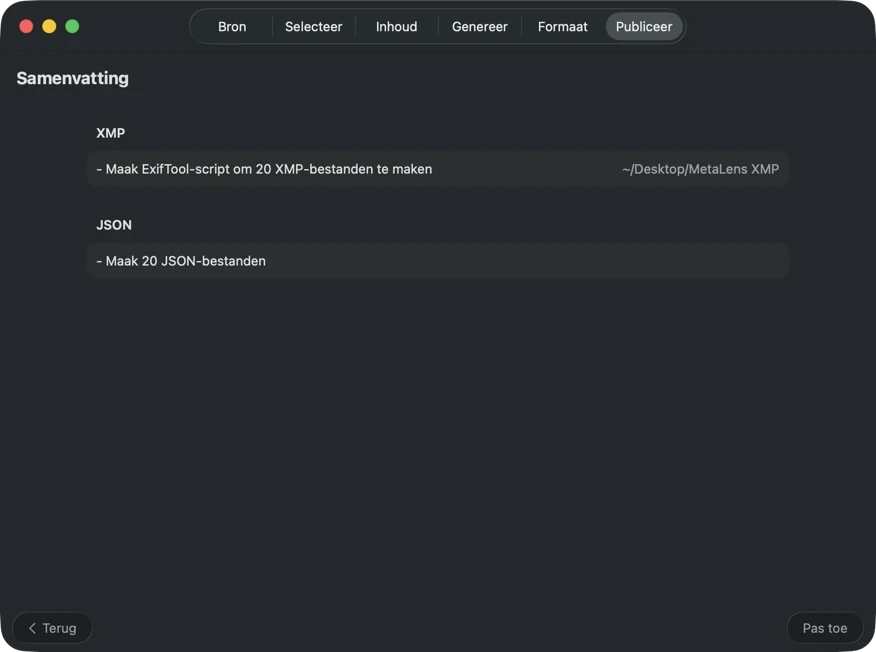
Bevestig voordat er iets wordt weggeschreven. Bekijk een duidelijke samenvatting van alle acties die worden uitgevoerd, inclusief waarschuwingen wanneer bestaande bestanden of metadata kunnen worden overschreven — en publiceer daarna om je geselecteerde outputs met vertrouwen toe te passen.
Eenmalige aankoop
Inclusief BTW
Veilig betalen via FastSpring