すべての画像にaltテキストを。自動で。
VisionTaggerはMac上で数百枚のWebサイト画像に対して正確で一貫したaltテキストを生成します。アクセシビリティとSEOを向上させながら、外部サービスへのアップロードは不要。画像単位の課金もありません。
macOS 26 の Apple Silicon Mac が必要
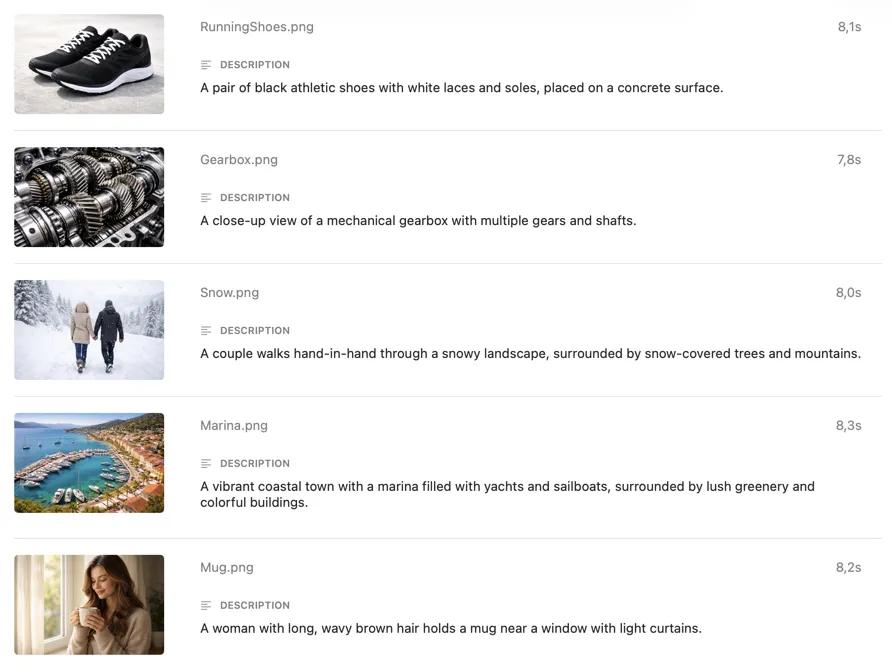

サイトにはaltテキストが必要。手作業では追いつかない。
アクセシビリティ基準では意味のある画像に説明的なaltテキストが求められ、良いaltテキストはSEOにも効果的です。しかし数百枚の画像に手動でaltテキストを書くのは遅く、一貫性がなく、締め切りが迫ると真っ先に後回しにされます。クラウドのジェネレーターは役立ちますが、画像を外部サーバーにアップロードし、画像ごとに課金されることを意味します。
サイト全体のaltテキストを — Macでプライベートに生成
VisionTaggerはAIモデルをローカルで実行し、画像を自動的に説明します。数百枚の画像を一括処理し、結果が届くそばからレビュー・編集し、ビルドパイプライン用に構造化されたaltテキストをエクスポート — アップロード不要、サブスクリプション不要、画像単位の課金なし。
数百枚の画像のaltテキストを一括生成
Webサイト画像のフォルダをVisionTaggerにドロップ、または写真ライブラリから画像を選択。1枚ずつ説明を書く代わりに、バッチ全体のaltテキストを一度に生成します。
すべての画像で一貫したトーンと長さ
内蔵スタイル(簡潔・標準・詳細)で始めるか、独自のルールを定義 — 長さ、トーン、含める内容や除外する内容。同じスタイルを数百枚の画像に適用して、一人が書いたように読めるaltテキストを実現します。
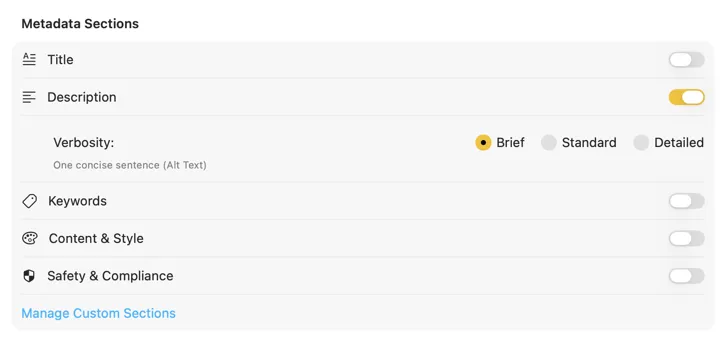
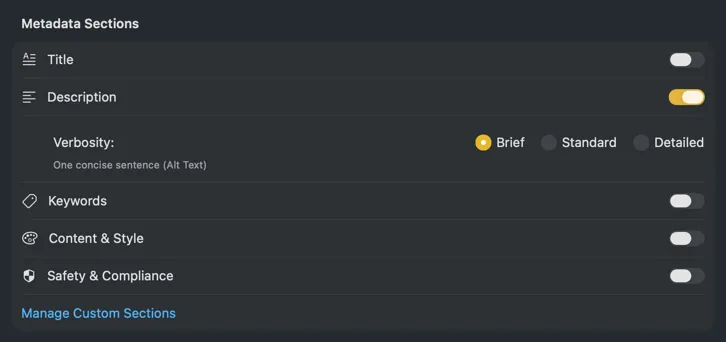
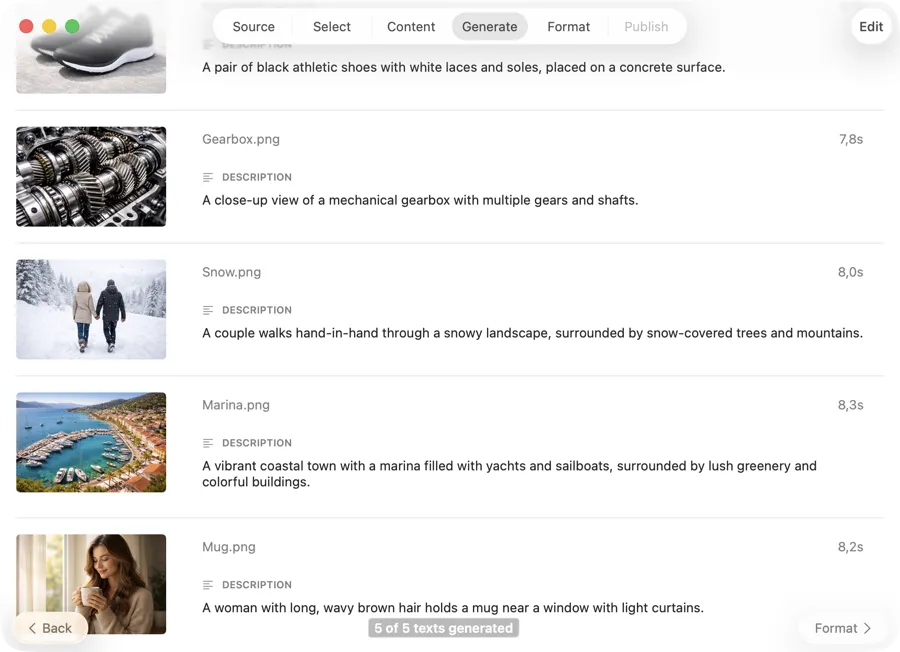
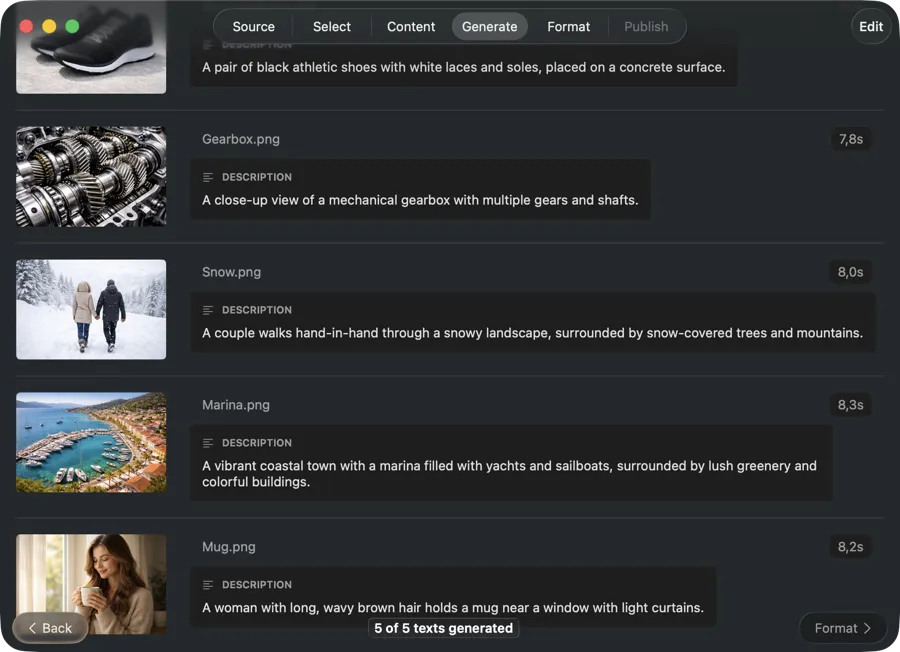
結果が届くそばからレビュー・編集
各画像の処理が完了するとaltテキストが表示されるので、バッチ全体を待たずに確認・編集・修正ができます。
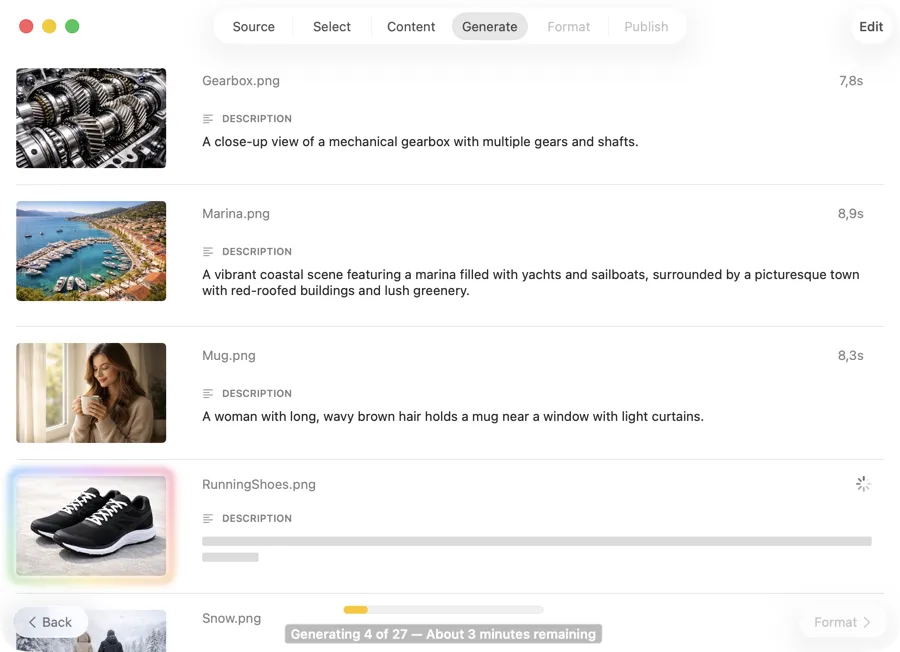
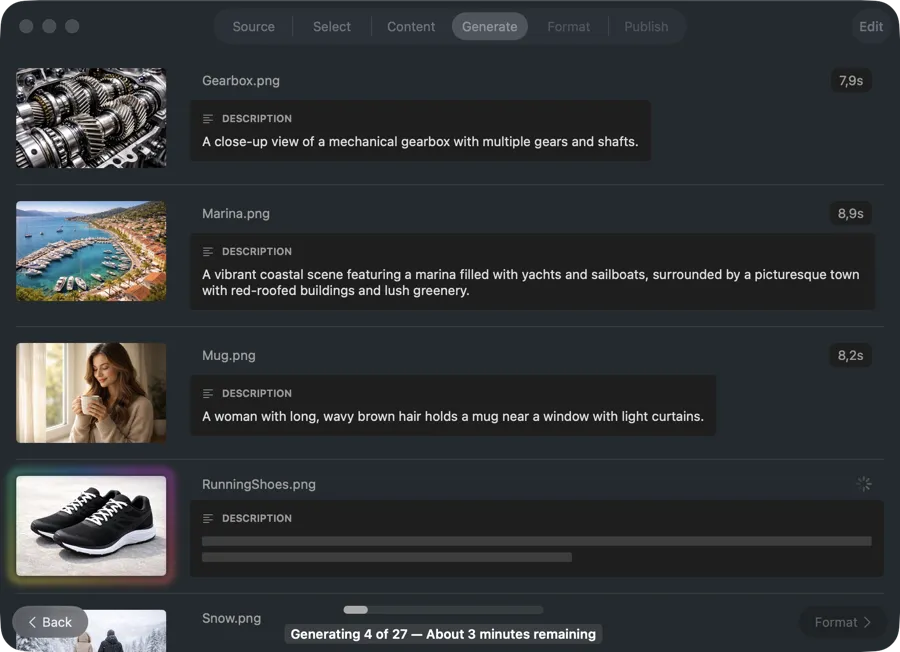
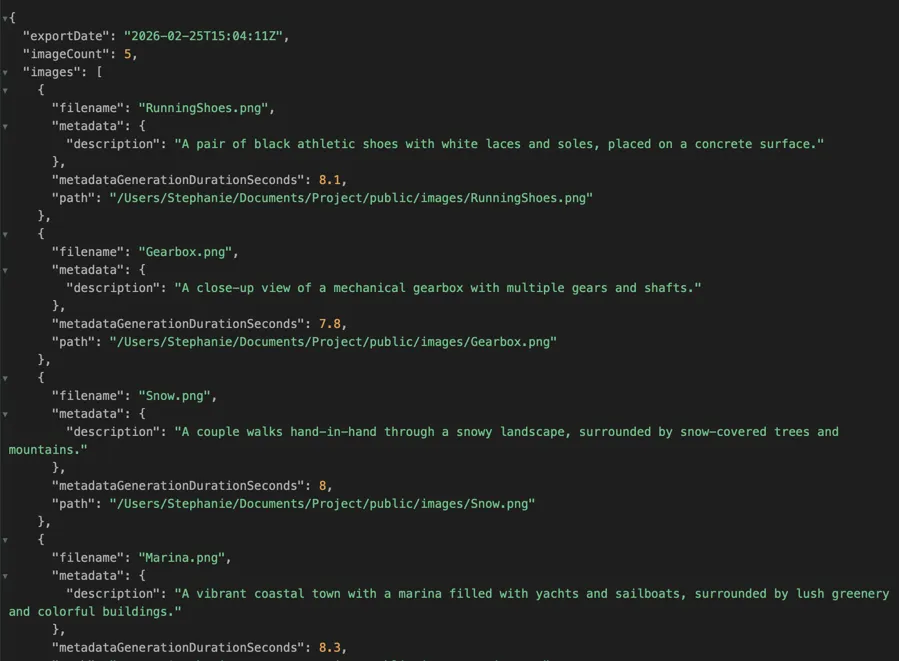
ビルドパイプラインにそのまま対応
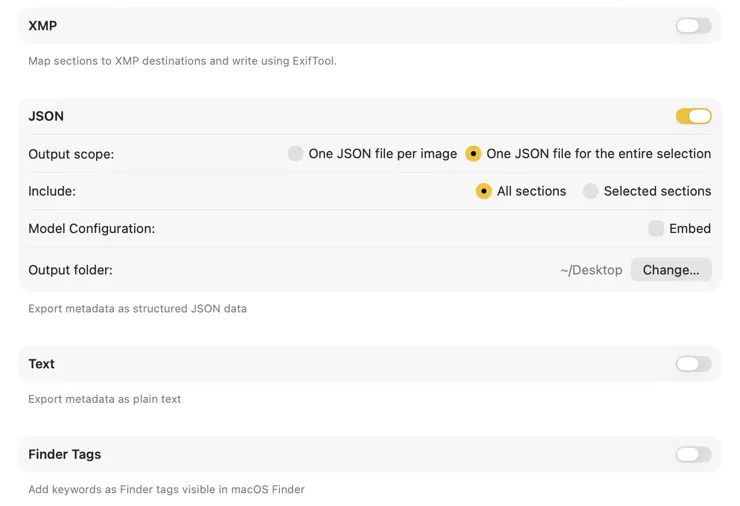
各画像パスと生成されたaltテキストを対応付けたJSONファイルをエクスポート — ビルドステップ、CMSインポート、コンポーネントライブラリにそのまま組み込めます。またはスプレッドシートベースのワークフロー用にCSVでエクスポート。
使用例

買い切り
VAT込み
FastSpring による安全な決済