Mai più taggare foto a mano.
VisionTagger usa l’IA on-device per generare titoli, descrizioni, parole chiave e altro per le tue immagini — in blocco, senza upload e senza costi per immagine.
Richiede un Mac Apple Silicon con macOS 26
Per chi è VisionTagger?
-
Designer che cercano tra gli asset dei progetti — tagga le immagini per mood, stile, soggetto e utilizzo per rendere la tua libreria di asset immediatamente ricercabile.
-
Ricercatori e archivisti che preservano collezioni — crea metadati strutturati e coerenti per dataset, registri e conservazione digitale a lungo termine.
Risultati migliori con il contesto che hai già
Dì all’IA cosa sta guardando e i risultati migliorano drasticamente. Aggiungi un Context Hint come “foto di prodotto per un negozio di mobili vintage,” attiva GPS Location per includere nomi di luoghi dalle coordinate incorporate, oppure passa metadati della fotocamera ed editoriali già presenti nei tuoi file. Ogni fonte è opzionale e viene inserita direttamente nel prompt — così l’IA non deve indovinare.
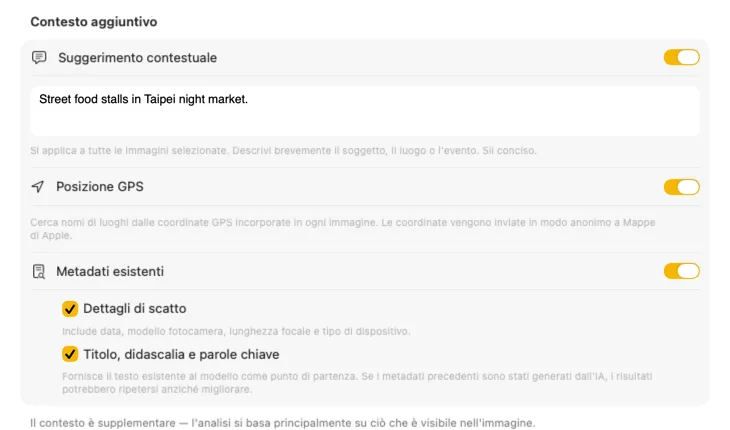
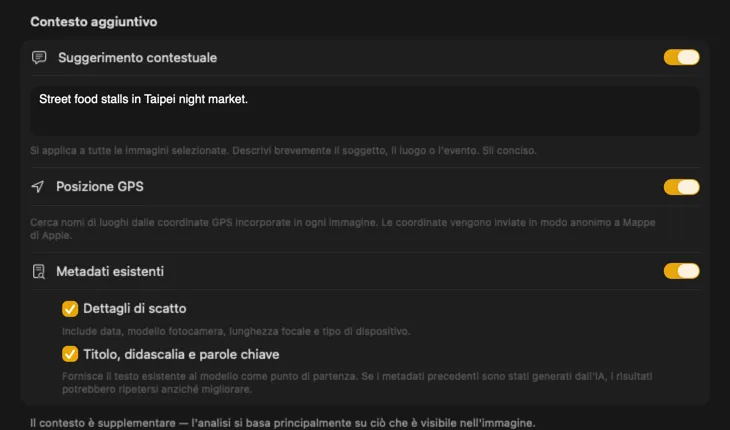
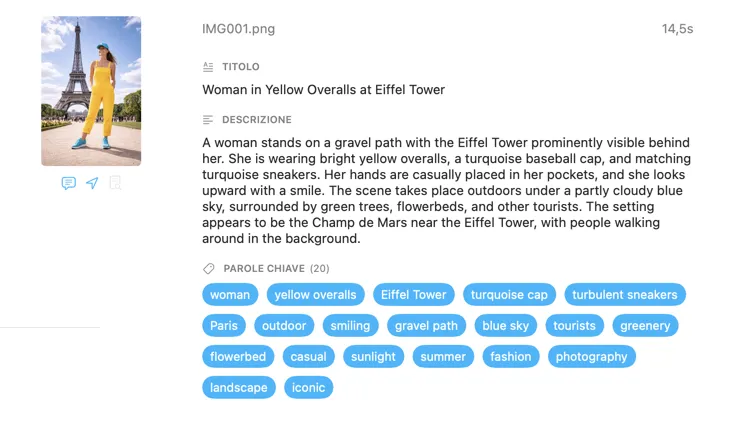
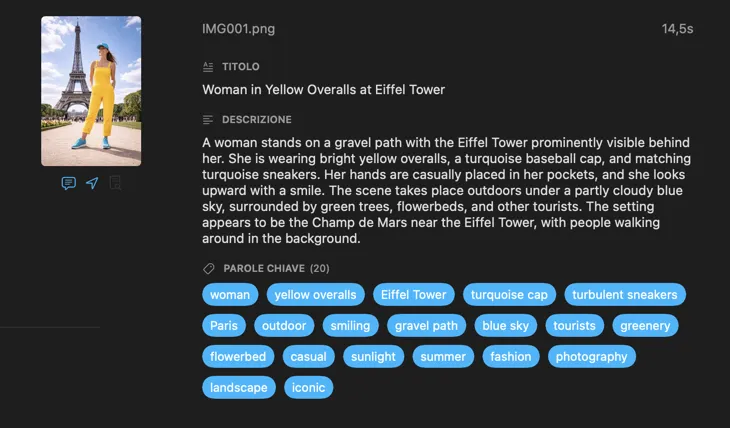
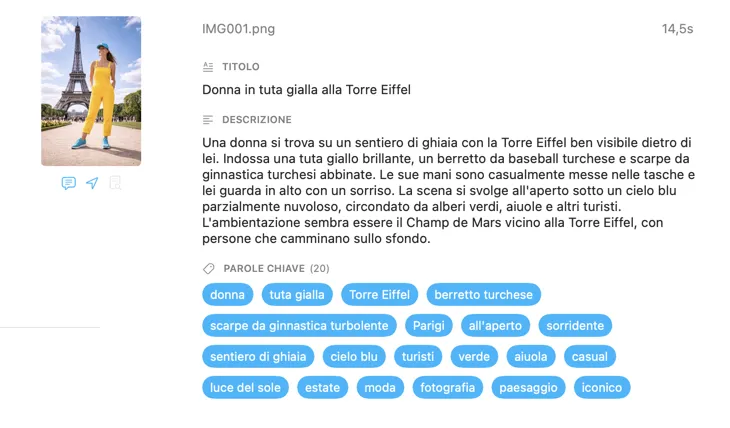
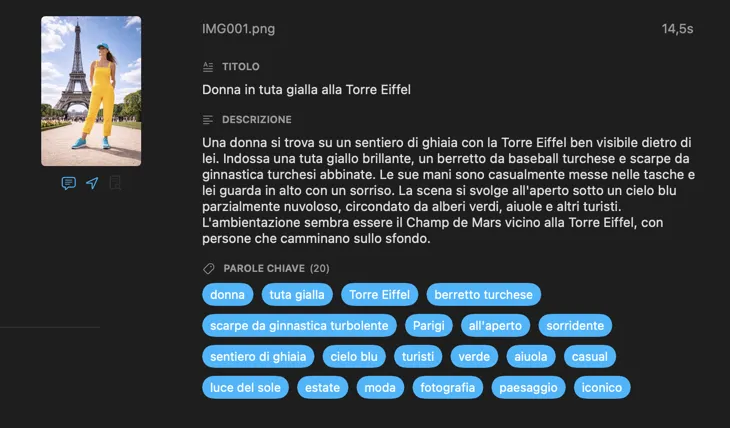
Genera esattamente i metadati di cui hai bisogno
Parti dai campi di cui la maggior parte delle persone ha bisogno — Titolo, Descrizione e Parole chiave — poi vai oltre con Contenuto e stile, Sicurezza e conformità, oppure aggiungi sezioni completamente personalizzate con i tuoi campi e prompt. Hai bisogno dell’output in un’altra lingua? VisionTagger può tradurre automaticamente i metadati generati usando la traduzione integrata di macOS. Il risultato sono metadati strutturati e coerenti su migliaia di foto.
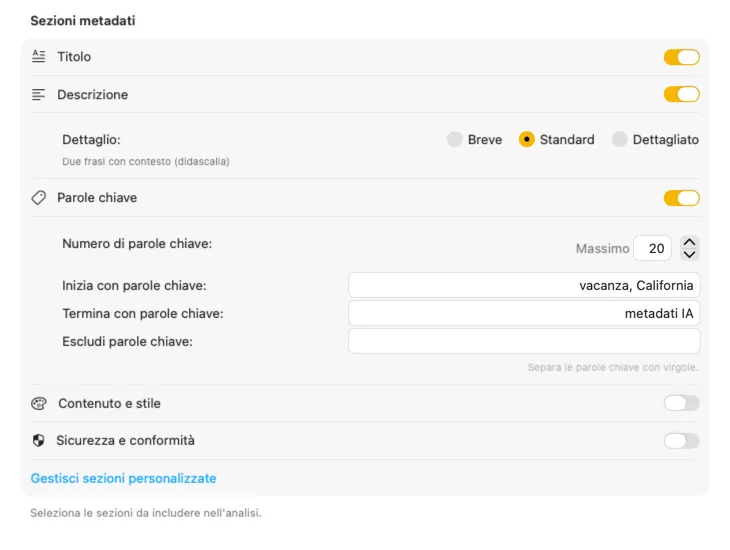
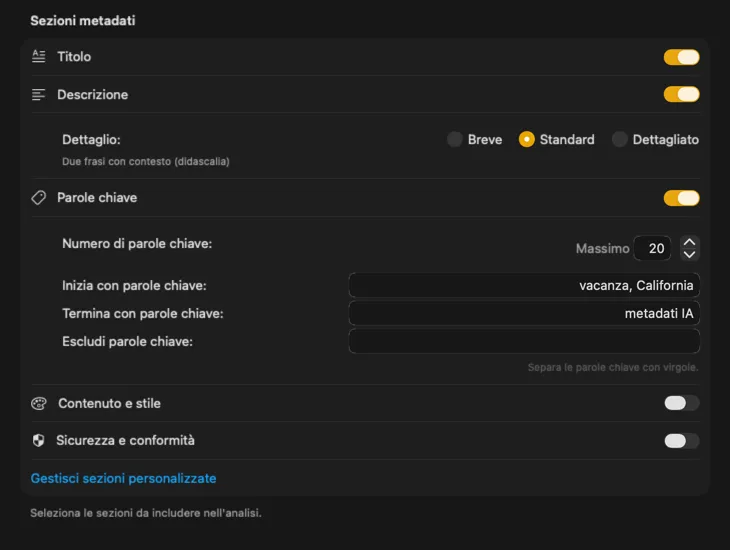
Si integra perfettamente nel tuo flusso di lavoro
Per sidecar XMP e metadati incorporati, VisionTagger si integra con ExifTool — un’utility standard del settore, ampiamente affidabile. I tuoi metadati compariranno in app come Adobe Lightroom, Bridge, Capture One, Photo Mechanic e in qualsiasi altro software che legga XMP. Scrivi nella tua libreria Foto, esporta JSON, CSV o TXT per immagine, oppure genera un singolo file per un intero batch. Aggiungi tag del Finder per un’organizzazione rapida in macOS. Seleziona più output insieme e configurali in un unico posto — così una sola passata di generazione può alimentare ogni destinazione che usi.
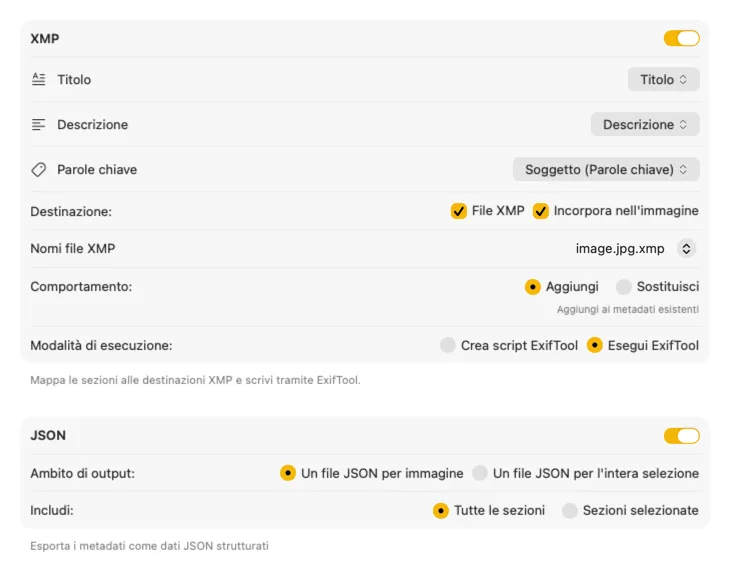
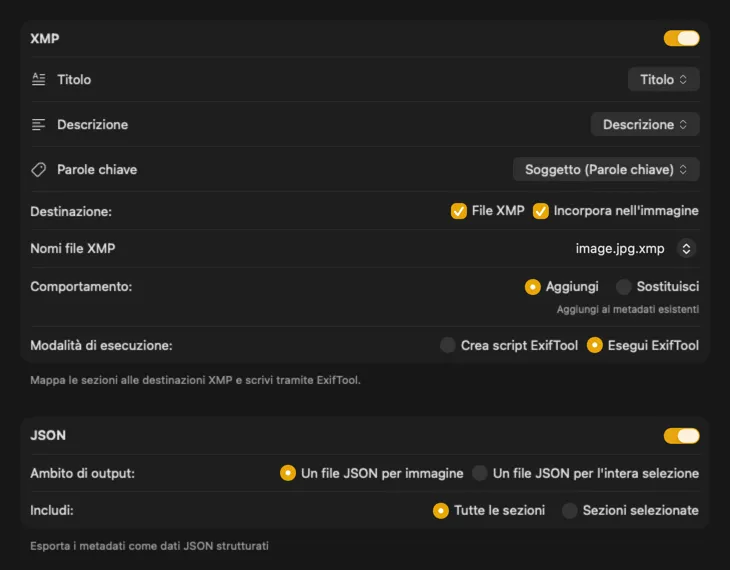
Automatizza e dimenticatene
Due azioni di Comandi Rapidi — una per i file nel Finder, una per la tua libreria Foto — ti permettono di eseguire il processo completo in background senza aprire l’app. Configura un’automazione di cartella, un’azione rapida del Finder, oppure avvialo dalla riga di comando. Usa le impostazioni attuali dell’app o fornisci un preset salvato per risultati riproducibili ogni volta.


Come funziona
Guarda la demo su YouTube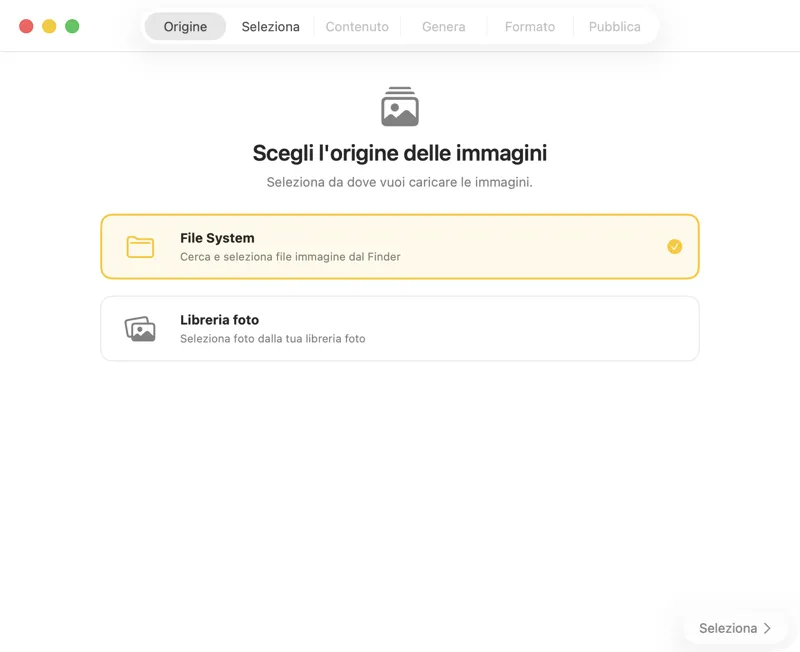
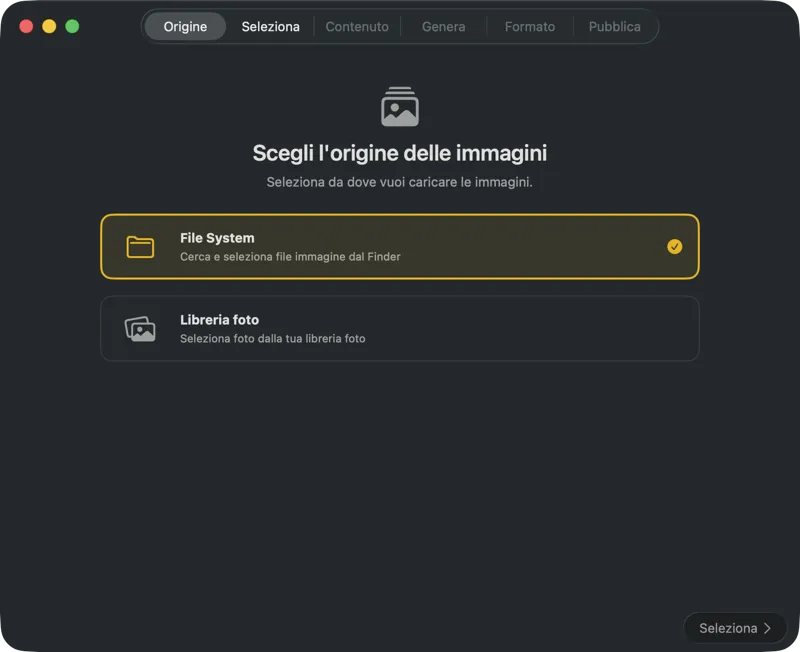
Scegli dove sono salvate le tue immagini — cartelle sul tuo Mac o la tua libreria Foto.
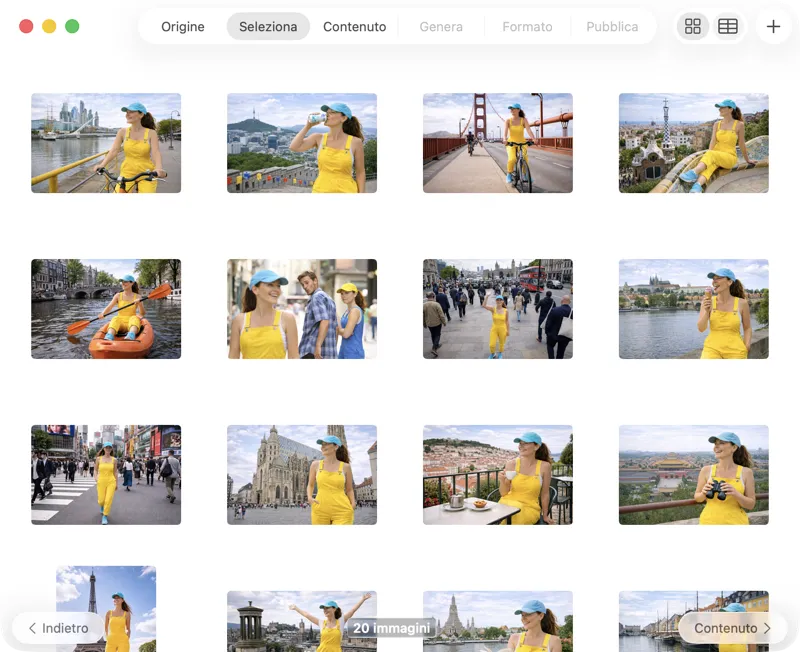
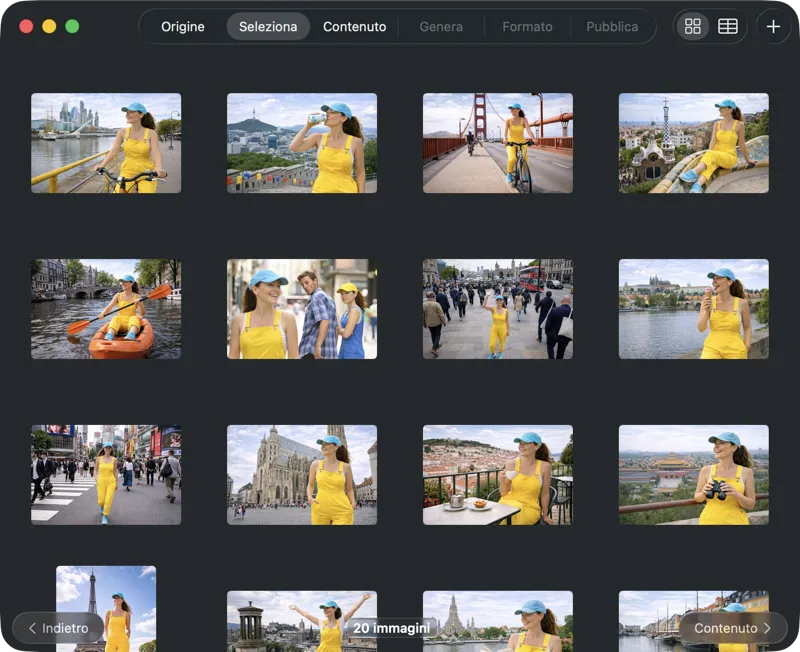
Scegli esattamente cosa vuoi elaborare. Sfoglia la selezione in vista griglia o tabella, aggiungi altre immagini con il pulsante di aggiunta oppure trascina e rilascia i file nell’app per creare un batch.
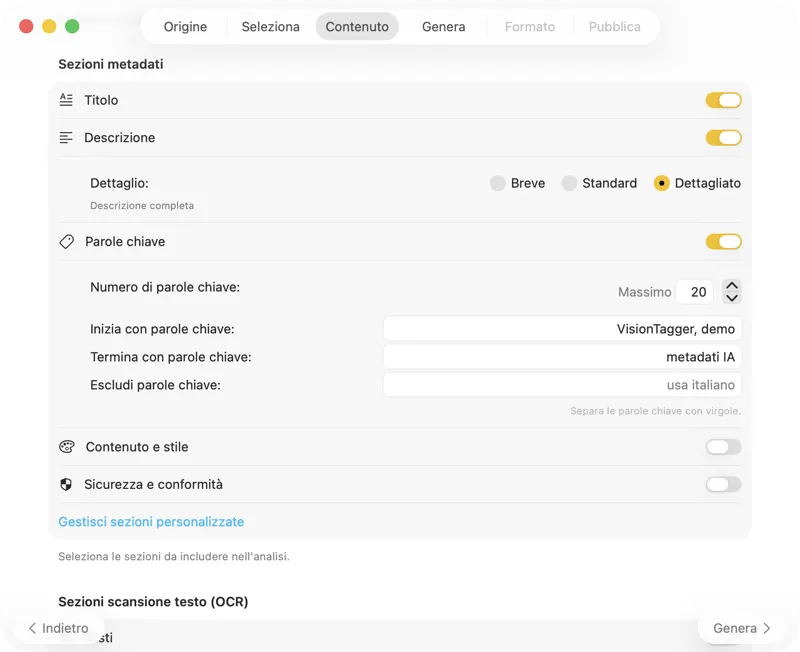
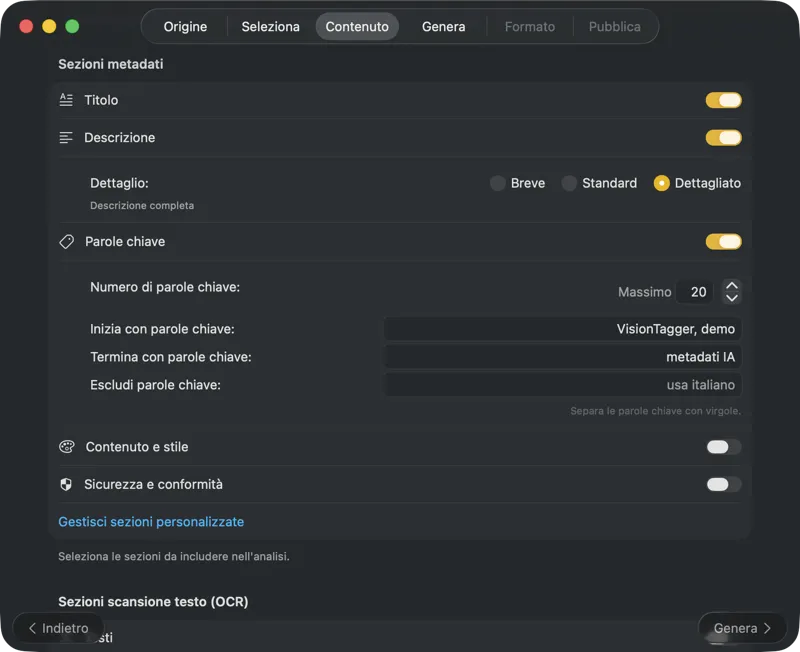
Scegli un modello IA (scaricane uno nell’app con un clic) e seleziona quali metadati generare: titoli, descrizioni, parole chiave, tag di stile, valutazioni di sicurezza o i tuoi campi personalizzati.
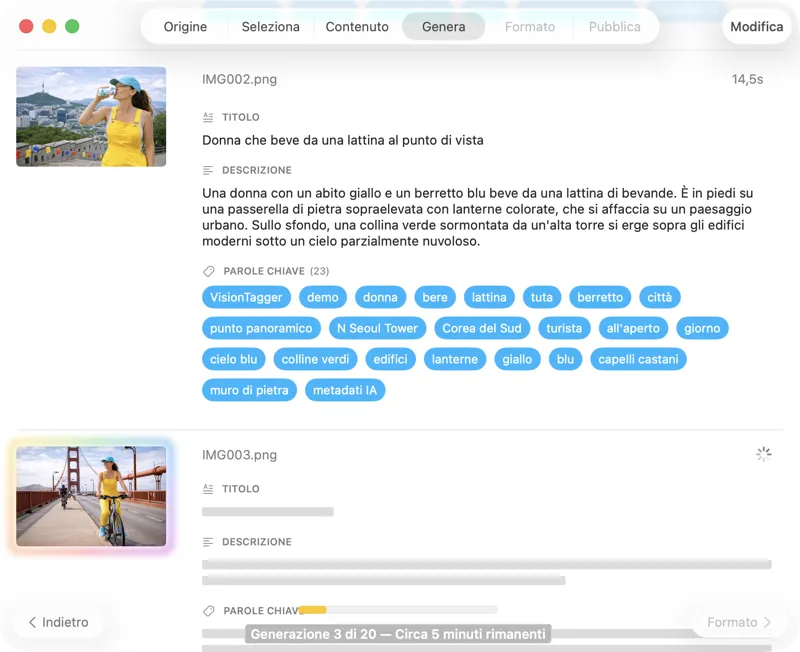
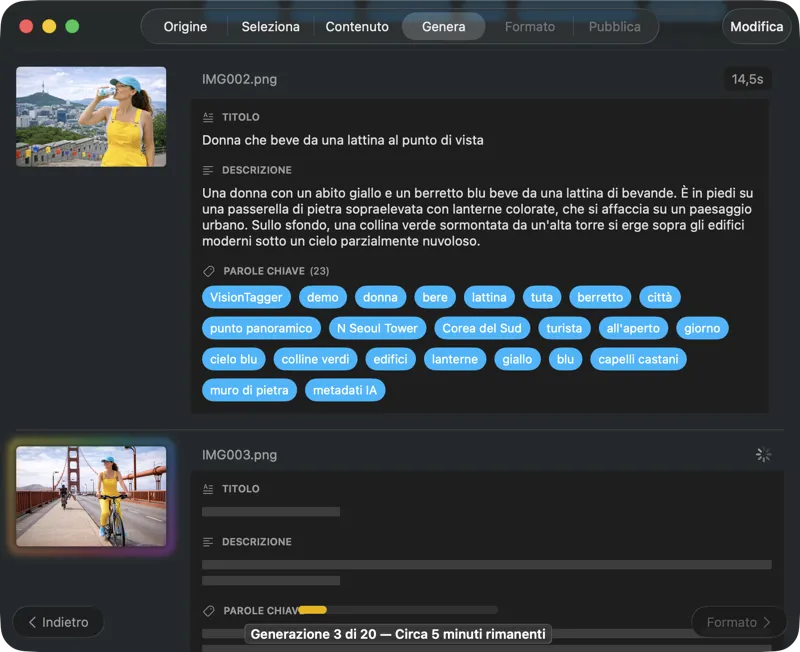
Guarda i risultati comparire in tempo reale. VisionTagger elabora le immagini in locale e invia in streaming i metadati generati in un elenco scorrevole non appena ogni elemento è pronto, così puoi rivedere e modificare gli output mentre il batch continua.
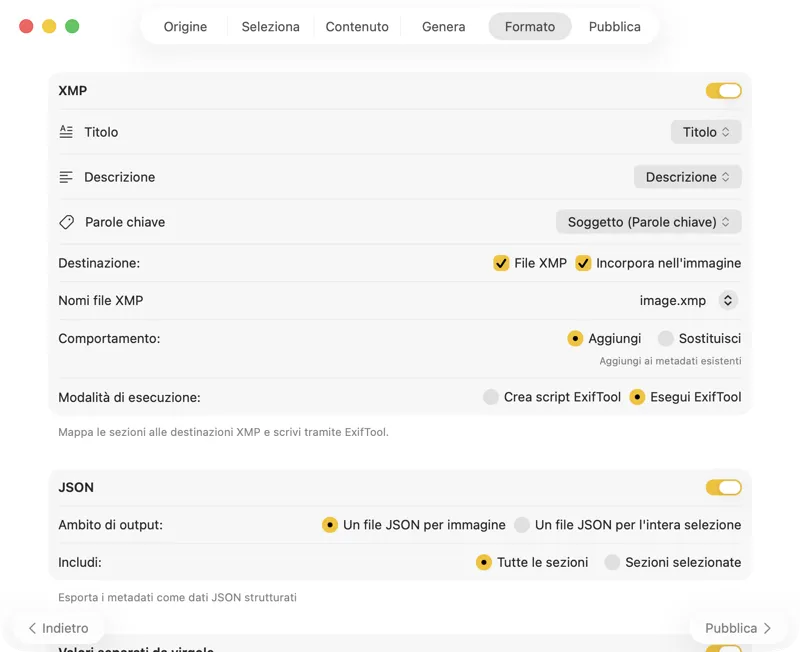
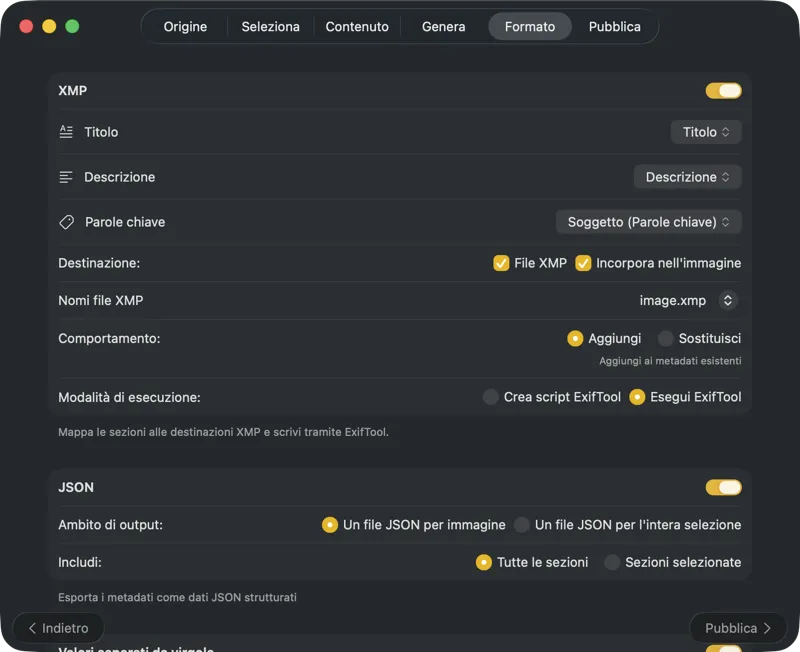
Scegli dove vanno i metadati: sidecar XMP per il tuo catalogo fotografico, JSON o CSV per la pipeline del tuo sito, tag del Finder, o scrivi su Foto. Seleziona più output contemporaneamente.
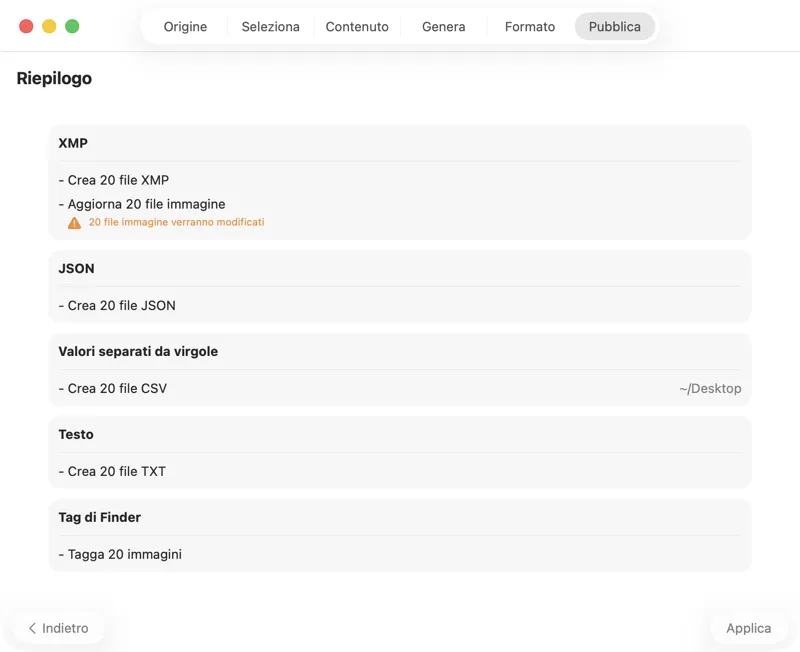
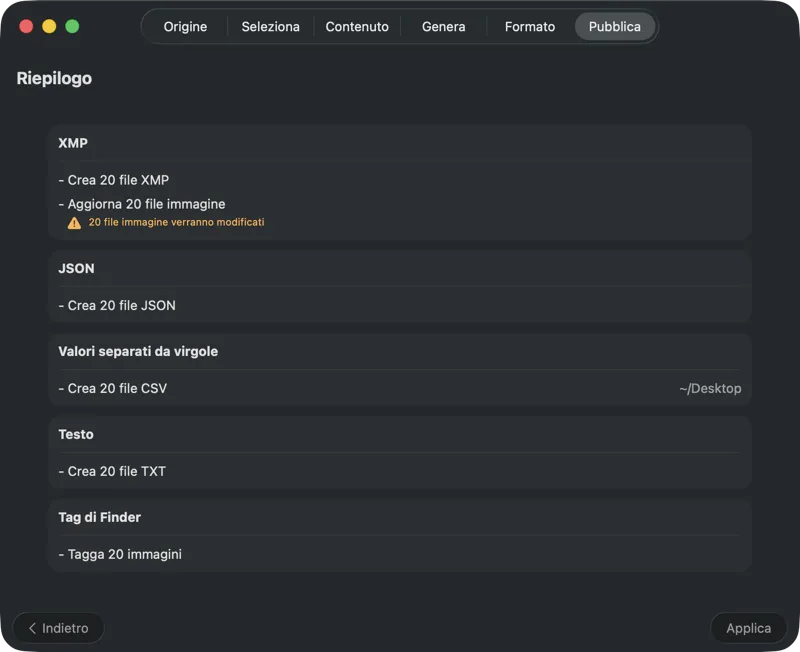
Conferma prima che venga scritto qualsiasi cosa. Rivedi un riepilogo chiaro di tutte le azioni che verranno eseguite, inclusi avvisi quando file o metadati esistenti potrebbero essere sovrascritti — poi pubblica per applicare con sicurezza gli output selezionati.
Acquisto una tantum
IVA inclusa (eccetto US & CA)
Pagamento sicuro tramite FastSpring