Ne taguez plus jamais vos photos à la main.
VisionTagger utilise une IA embarquée pour générer titres, descriptions, mots-clés et plus encore pour vos images — en masse, sans téléversement et sans frais par image.
Nécessite un Mac Apple Silicon avec macOS 26

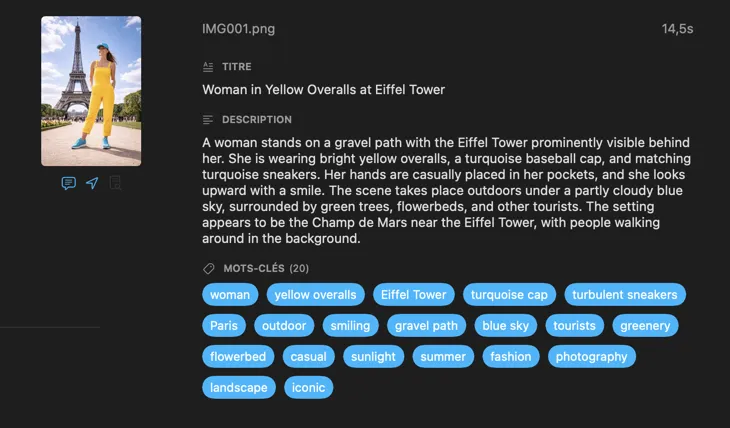
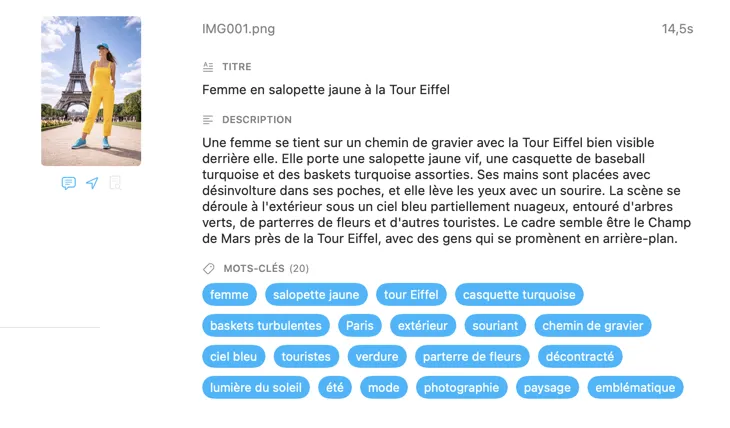
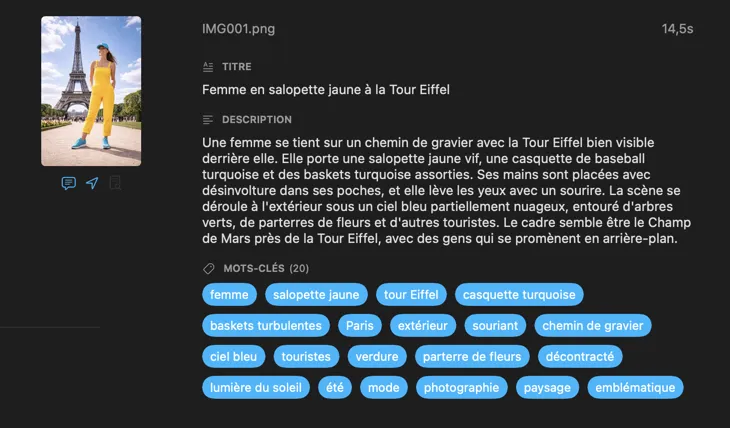
Pour qui est VisionTagger ?
-
Designers qui cherchent dans les fichiers de projet — taguez les images par ambiance, style, sujet et usage pour rendre votre bibliothèque d’assets instantanément consultable.
-
Chercheurs et archivistes qui préservent des collections — créez des métadonnées structurées et cohérentes pour des jeux de données, des dossiers et la préservation numérique à long terme.
Des résultats plus intelligents grâce au contexte que vous avez déjà
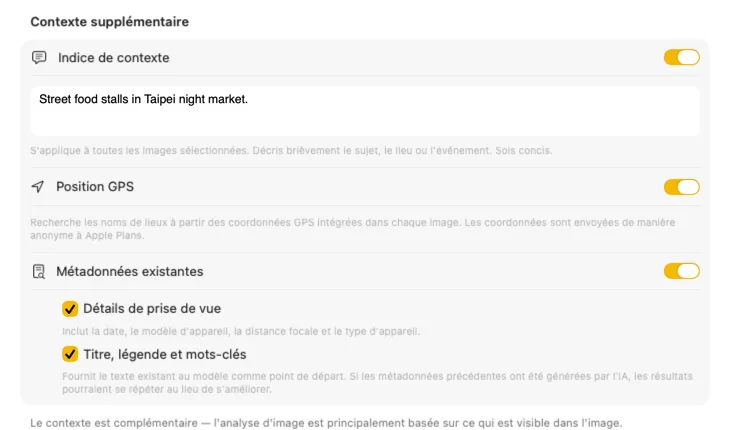
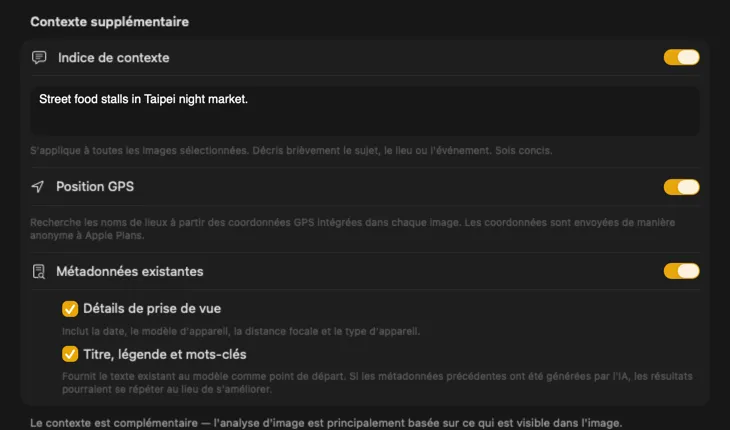
Dites à l’IA ce qu’elle regarde et les résultats s’améliorent radicalement. Ajoutez un Context Hint comme « photos de produits pour un magasin de meubles vintage », activez GPS Location pour inclure des noms de lieux à partir des coordonnées intégrées, ou transmettez les métadonnées de prise de vue et éditoriales déjà présentes dans vos fichiers. Chaque source est optionnelle et alimente directement le prompt — l’IA n’a plus à deviner.
Générez exactement les métadonnées dont vous avez besoin
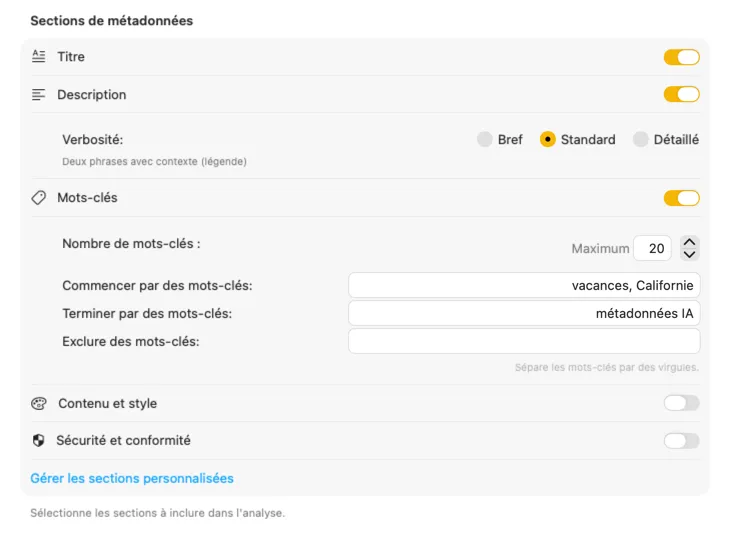
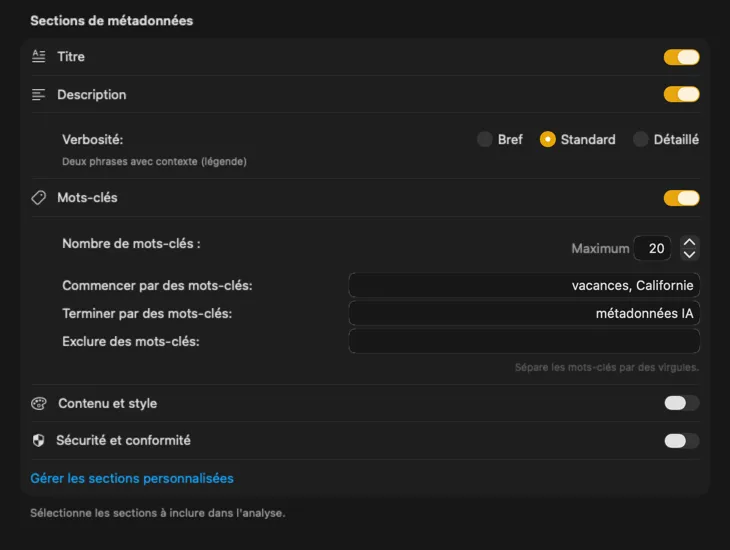
Commencez avec les champs dont la plupart des gens ont besoin — Titre, Description et Mots-clés — puis allez plus loin avec Contenu & Style, Sécurité & Conformité, ou ajoutez des sections entièrement personnalisées avec vos propres champs et prompts. Besoin d’une sortie dans une autre langue ? VisionTagger peut traduire automatiquement les métadonnées générées grâce à la traduction intégrée de macOS. Le résultat : des métadonnées structurées et cohérentes sur des milliers de photos.
S’intègre parfaitement dans votre workflow
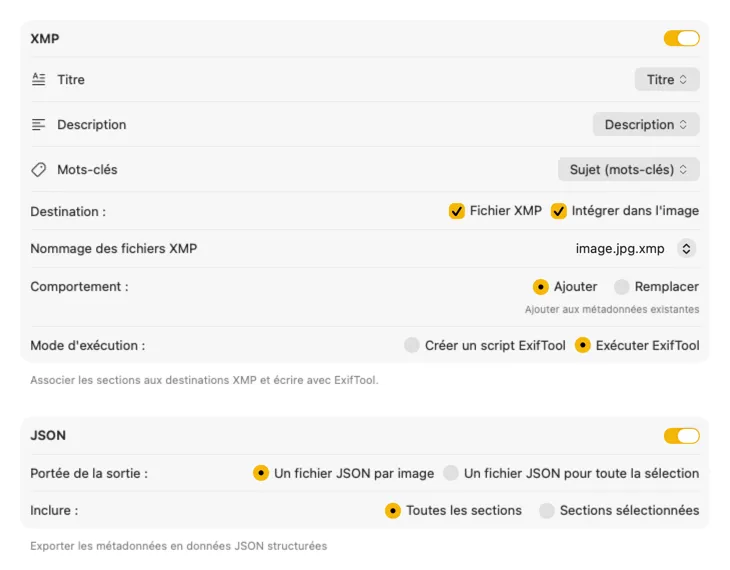
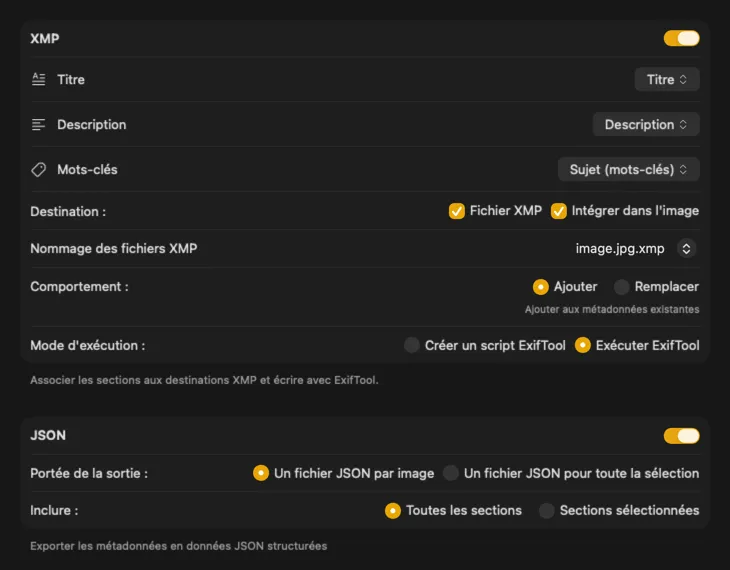
Pour les sidecars XMP et les métadonnées intégrées, VisionTagger s’intègre avec ExifTool — un utilitaire standard de l’industrie, largement reconnu. Vos métadonnées apparaîtront dans des apps comme Adobe Lightroom, Bridge, Capture One, Photo Mechanic, et tout autre logiciel qui lit l’XMP. Réécrivez dans votre photothèque Photos, exportez du JSON, du CSV ou du TXT par image, ou générez un seul fichier pour tout un lot. Ajoutez des tags Finder pour une organisation rapide dans macOS. Sélectionnez plusieurs sorties à la fois et configurez-les ensemble — pour qu’une seule passe de génération alimente toutes les destinations que vous utilisez.
Automatisez et oubliez
Deux actions Raccourcis — une pour les fichiers dans le Finder, une pour votre photothèque Photos — vous permettent d’exécuter le processus complet en arrière-plan sans ouvrir l’app. Configurez une automatisation de dossier, une action rapide Finder, ou déclenchez-la depuis la ligne de commande. Utilisez les réglages actuels de l’app ou fournissez un preset sauvegardé pour des résultats reproductibles à chaque fois.

Comment ça marche
Voir la démo sur YouTube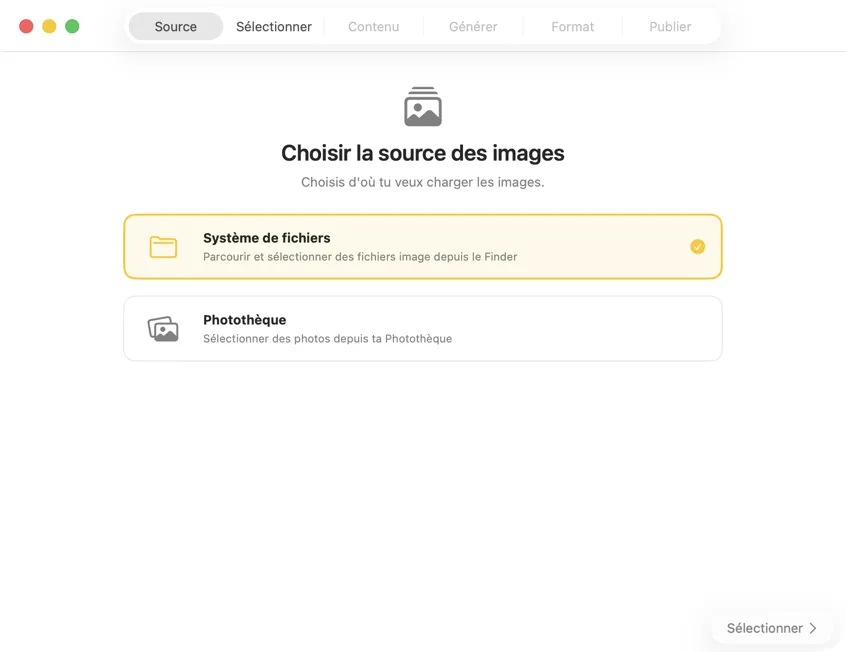
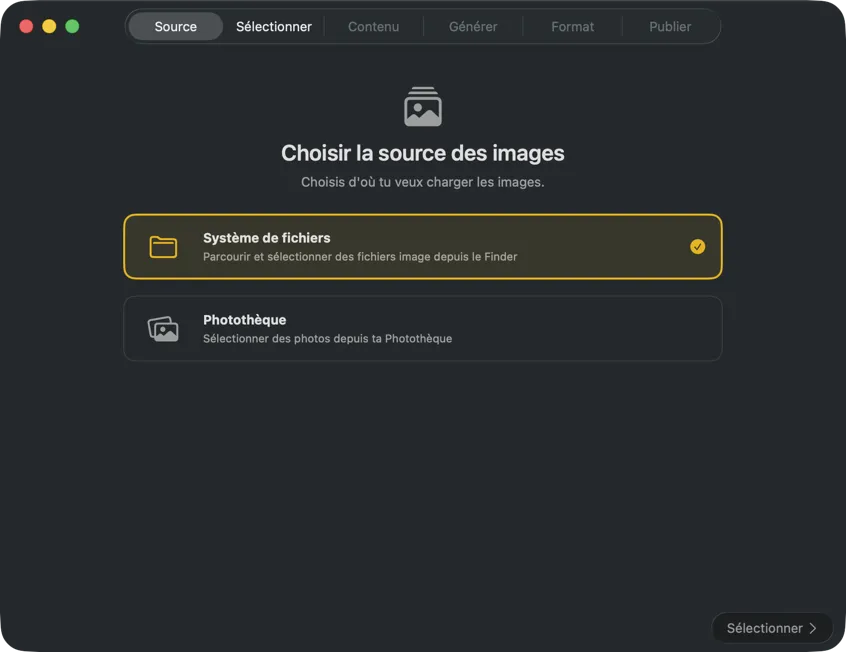
Choisis où tes images sont stockées — des dossiers sur ton Mac ou ta photothèque Photos.
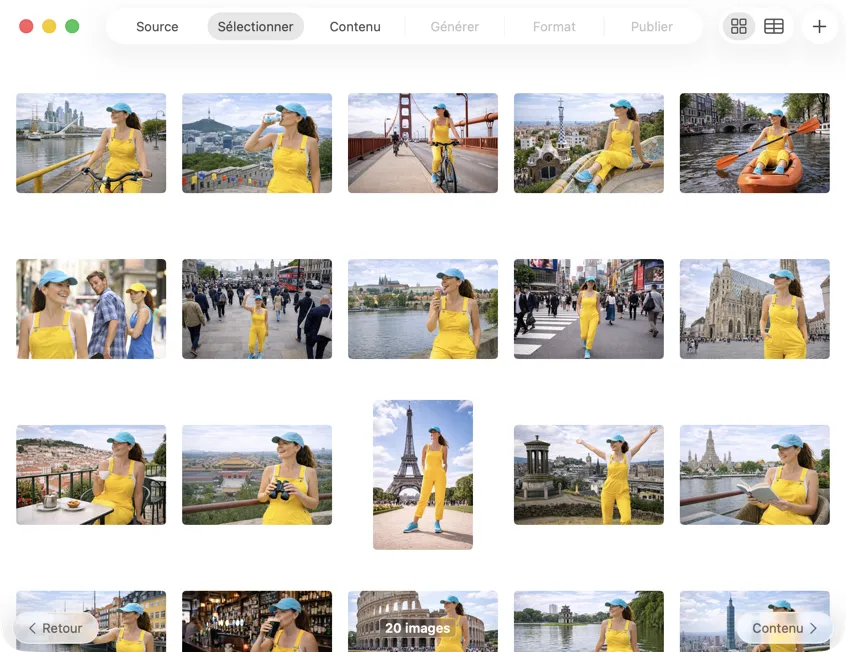
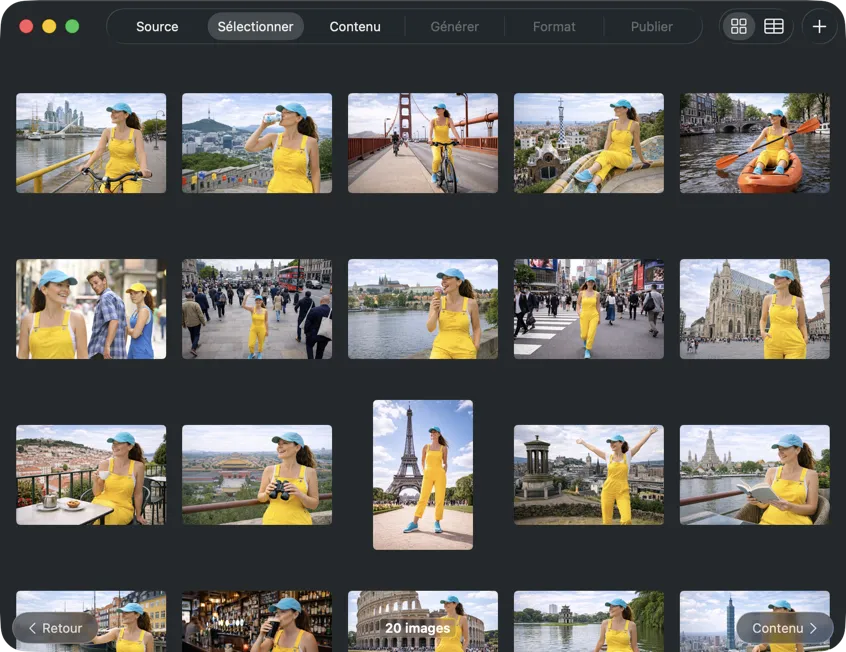
Choisis exactement ce que tu veux traiter. Parcours ta sélection en vue grille ou tableau, ajoute d’autres images via le bouton d’ajout, ou fais glisser-déposer des fichiers dans l’app pour constituer un batch.
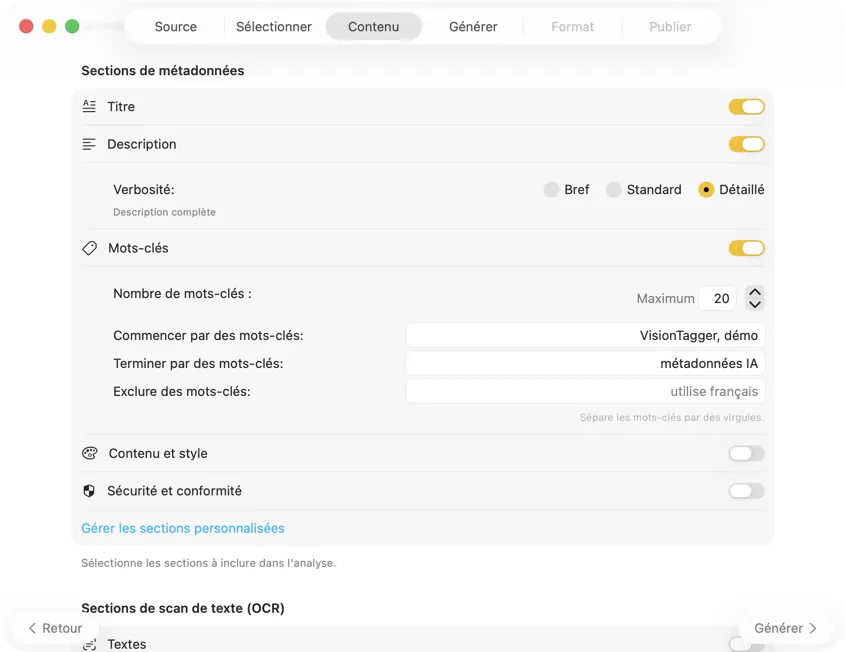
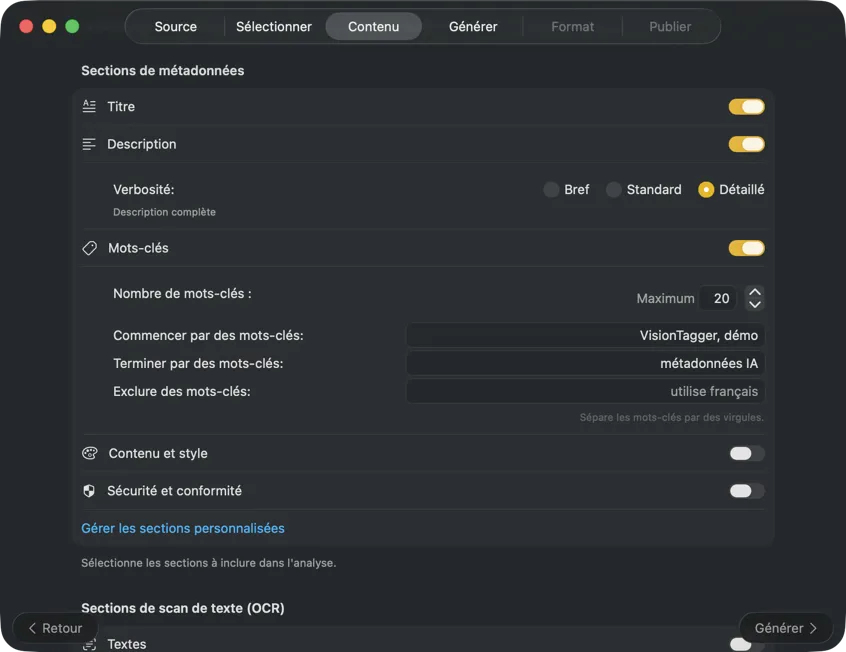
Choisis un modèle IA (télécharges-en un dans l’app en un clic) et sélectionne les métadonnées à générer : titres, descriptions, mots-clés, tags de style, classifications de sécurité ou tes propres champs personnalisés.
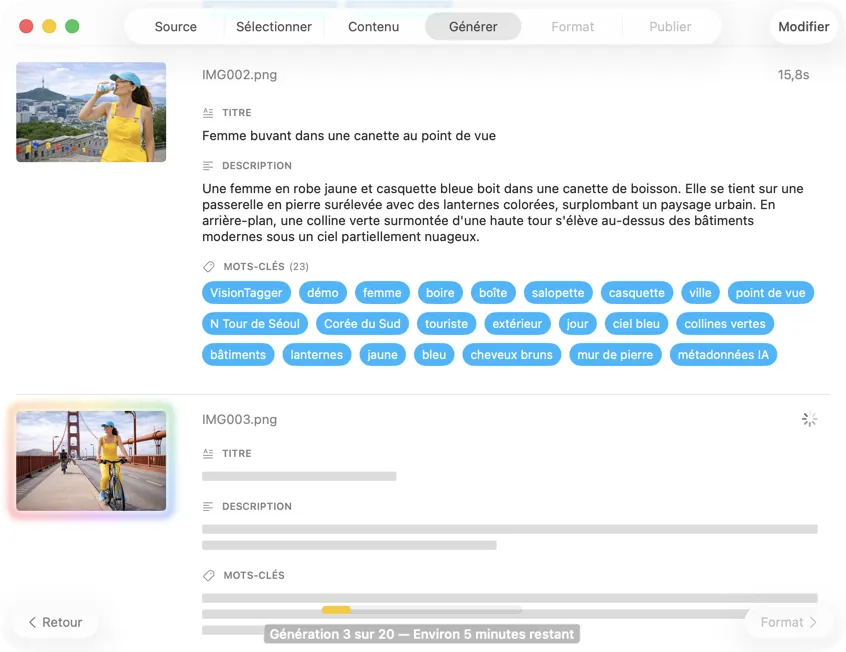
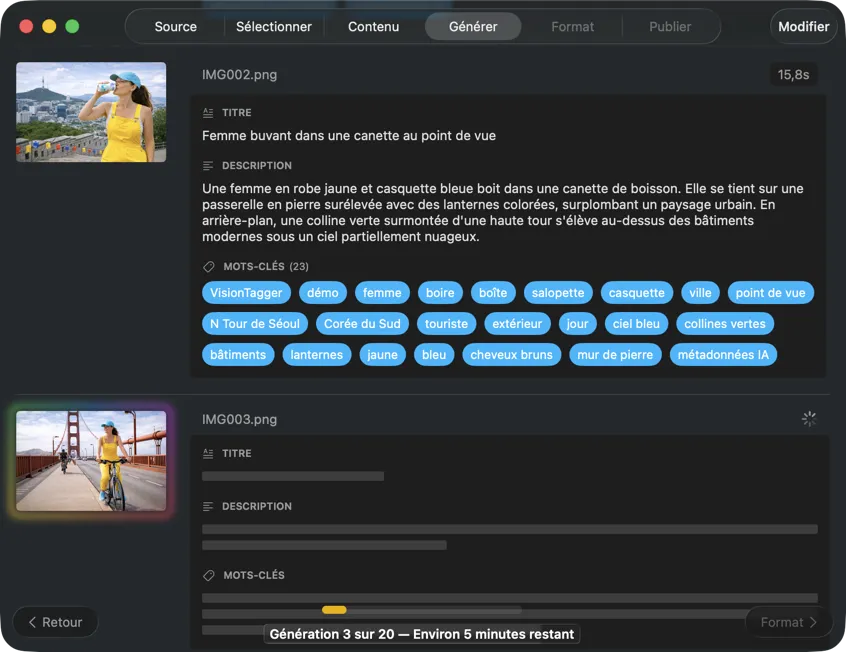
Regarde les résultats apparaître en temps réel. VisionTagger traite les images en local et diffuse les métadonnées générées dans une liste qui défile dès que chaque élément est prêt, donc tu peux revoir et modifier les sorties pendant que le batch continue.
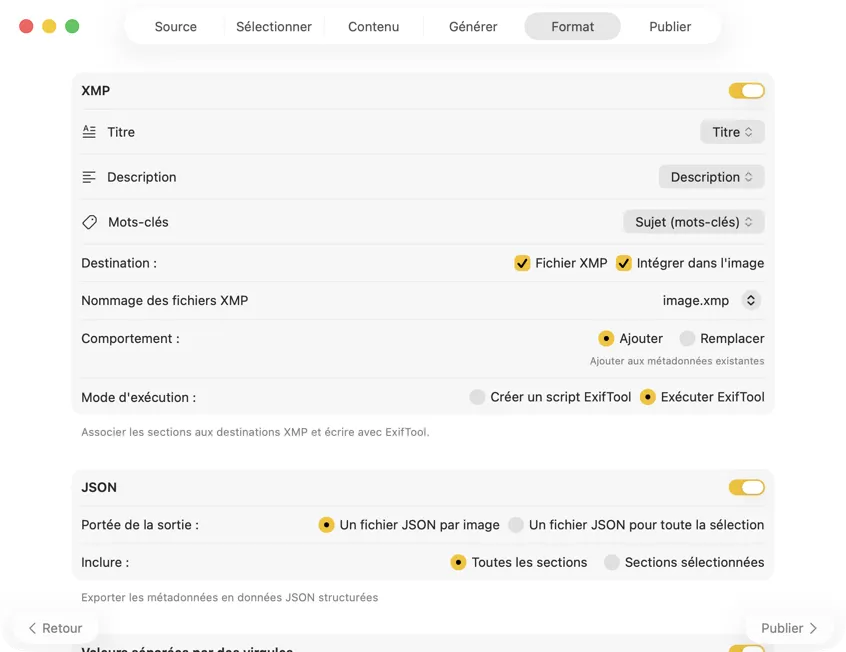
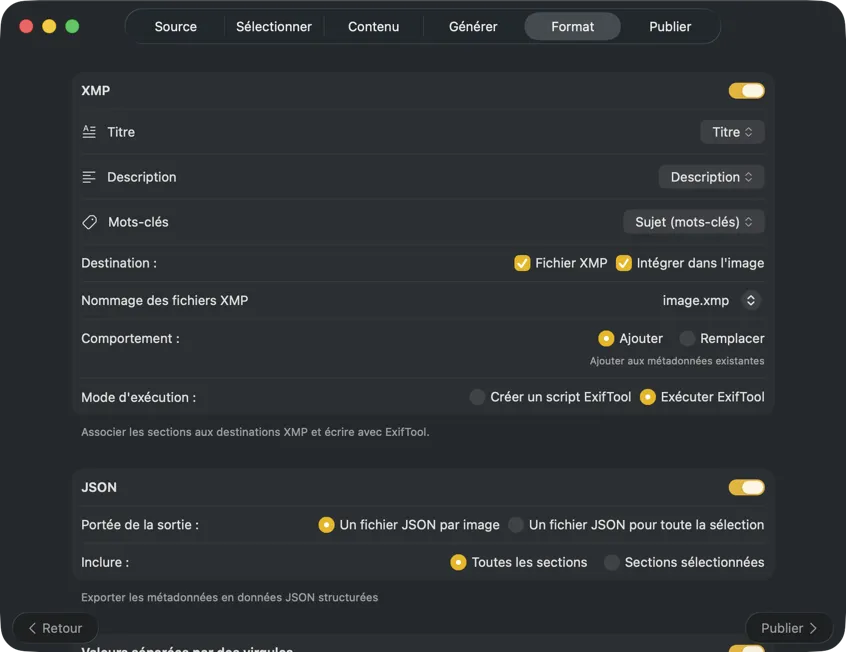
Choisis où vont les métadonnées : sidecars XMP pour ton catalogue photo, JSON ou CSV pour ton pipeline web, tags Finder, ou réécriture dans Photos. Sélectionne plusieurs sorties à la fois.
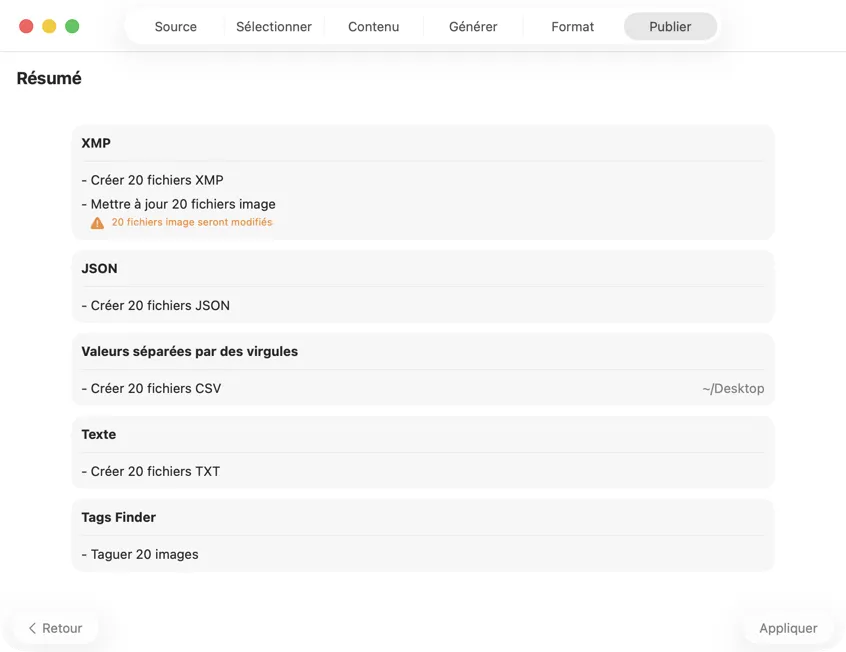
Confirme avant que quoi que ce soit soit écrit. Passe en revue un récap clair de toutes les actions qui vont être exécutées, avec des avertissements quand des fichiers ou des métadonnées existants risquent d’être écrasés — puis publie pour appliquer tes sorties sélectionnées en toute confiance.
Achat unique
TVA incluse
Paiement sécurisé via FastSpring