Nunca más etiquetes fotos a mano.
VisionTagger usa IA en el dispositivo para generar títulos, descripciones, palabras clave y más para tus imágenes — en lote, sin subidas y sin coste por imagen.
Requiere un Mac Apple Silicon con macOS 26


¿Para quién es VisionTagger?
-
Diseñadores que buscan entre recursos de proyectos — etiquetan imágenes por estado de ánimo, estilo, tema y uso para hacer su biblioteca de recursos instantáneamente buscable.
-
Investigadores y archivistas que preservan colecciones — crean metadatos estructurados y consistentes para conjuntos de datos, registros y preservación digital a largo plazo.
Mejores resultados con el contexto que ya tienes
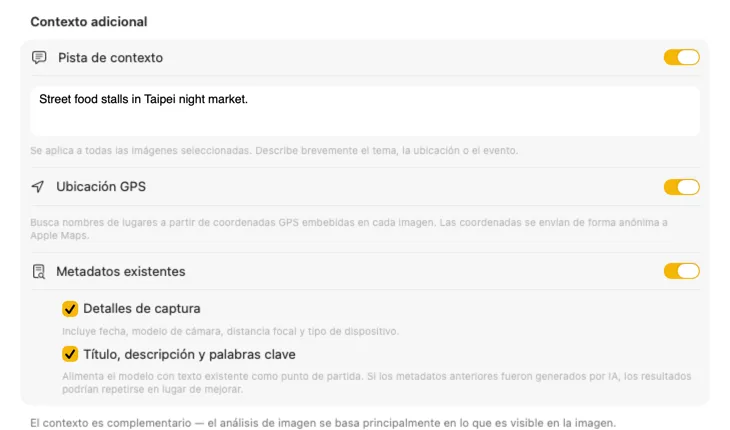
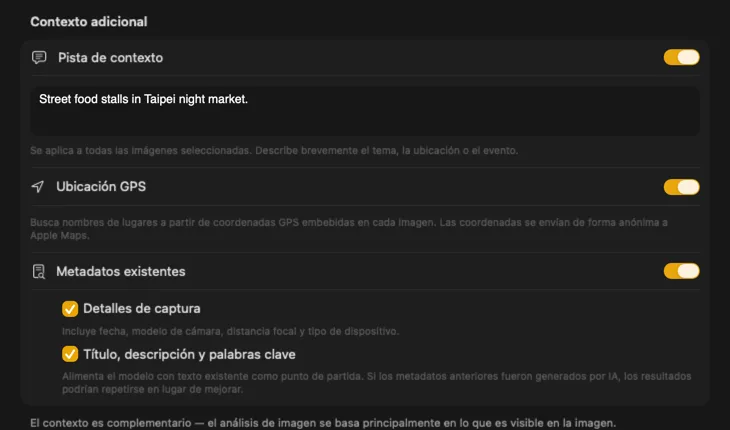
Dile a la IA qué está viendo y los resultados mejoran drásticamente. Añade un Context Hint como “fotos de producto para una tienda de muebles vintage”, activa GPS Location para incluir nombres de lugares a partir de coordenadas incrustadas, o pasa metadatos de cámara y editoriales que ya están en tus archivos. Cada fuente es opcional y se incorpora directamente al prompt — para que la IA no tenga que adivinar.
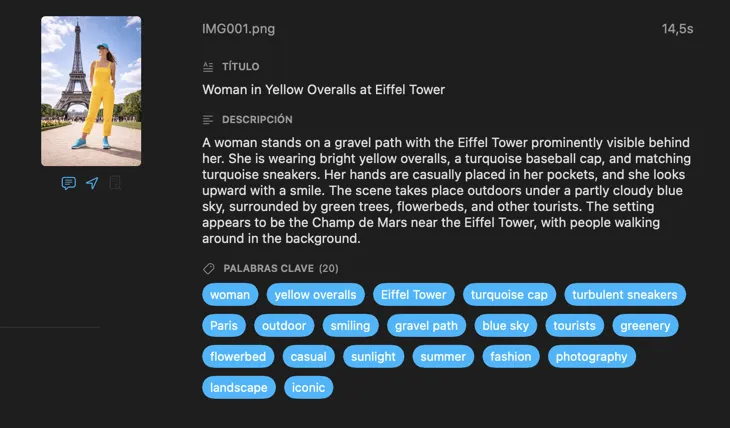
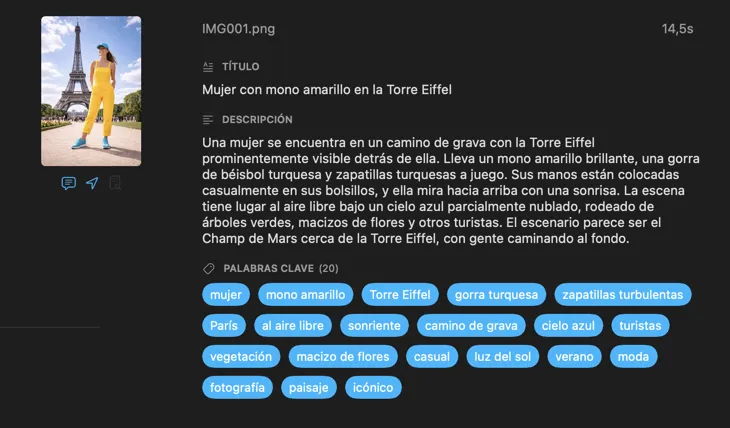
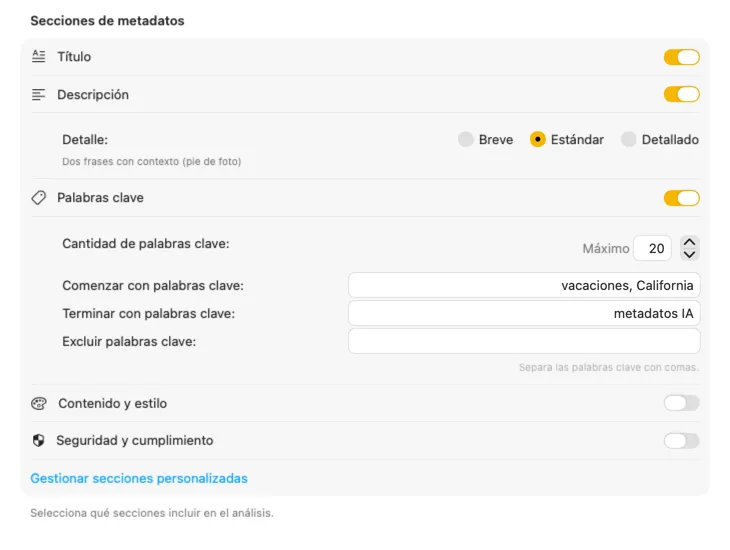
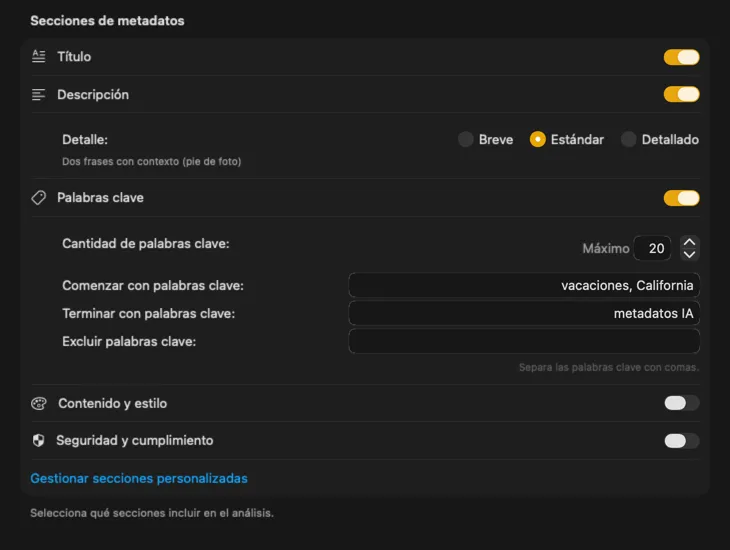
Genera exactamente los metadatos que necesitas
Empieza con los campos que más se necesitan — Título, Descripción y Palabras clave — y luego ve más allá con Contenido y estilo, Seguridad y cumplimiento, o añade secciones completamente personalizadas con tus propios campos y prompts. ¿Necesitas la salida en otro idioma? VisionTagger puede traducir automáticamente los metadatos generados usando la traducción integrada de macOS. El resultado son metadatos estructurados y consistentes en miles de fotos.
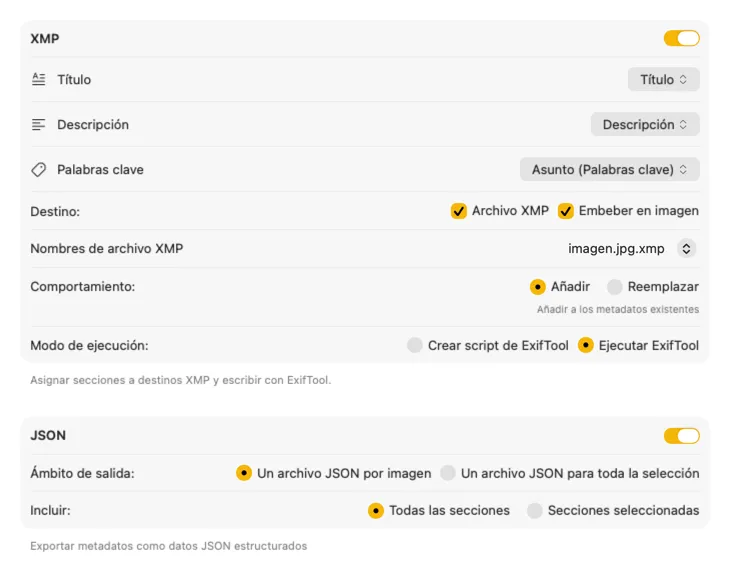
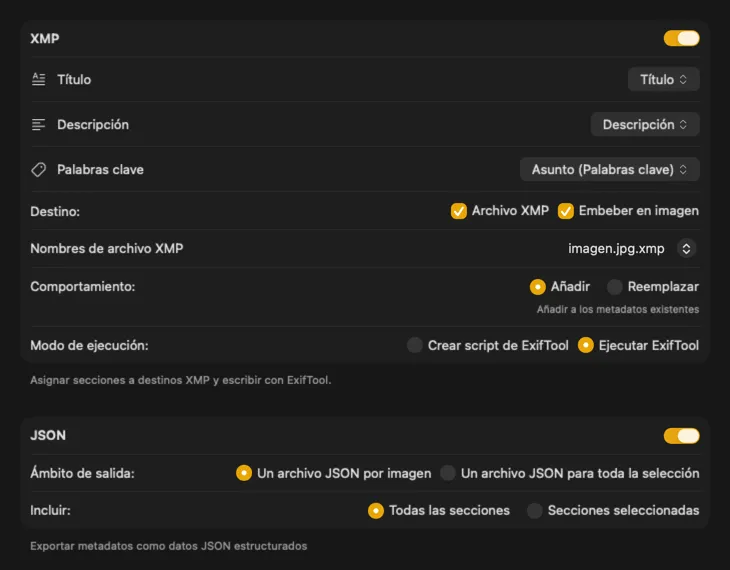
Encaja perfecto en tu flujo de trabajo
Para sidecars XMP y metadatos incrustados, VisionTagger se integra con ExifTool — una utilidad estándar del sector y ampliamente confiable. Tus metadatos aparecerán en apps como Adobe Lightroom, Bridge, Capture One, Photo Mechanic y cualquier otro software que lea XMP. Escribe de vuelta en tu Fototeca, exporta JSON, CSV o TXT por imagen, o genera un único archivo para toda una ejecución. Añade etiquetas de Finder para organizarte rápido en macOS. Selecciona varias salidas a la vez y configúralas juntas — para que una sola pasada de generación alimente todos los destinos que uses.
Automatízalo y olvídate
Dos acciones de Atajos — una para archivos en Finder, otra para tu Fototeca — te permiten ejecutar el proceso completo en segundo plano sin abrir la app. Configura una automatización de carpeta, una acción rápida del Finder, o ejecútalo desde la línea de comandos. Usa los ajustes actuales de la app o proporciona un preset guardado para resultados reproducibles en todo momento.

Cómo funciona
Ver demo en YouTube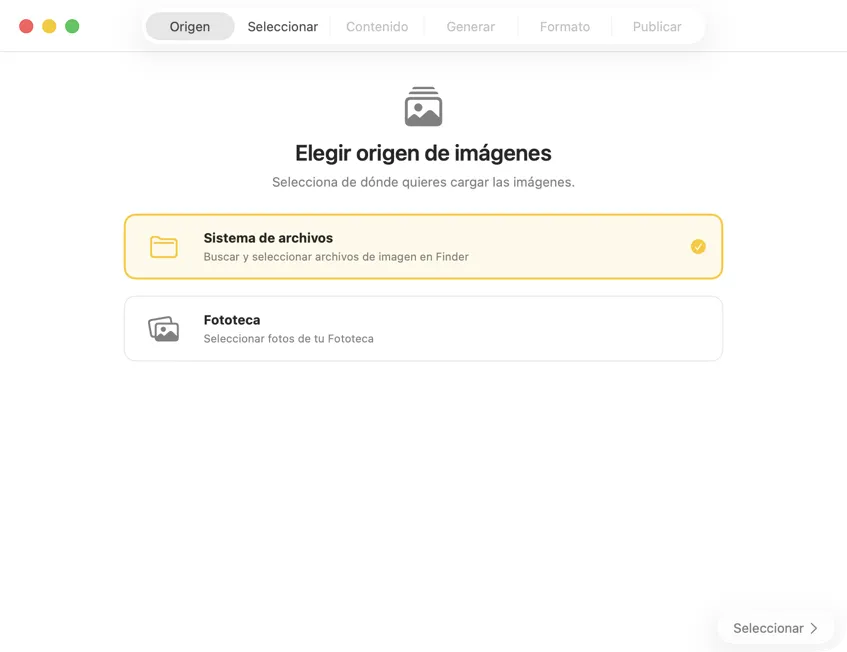
Elige dónde están guardadas tus imágenes — carpetas en tu Mac o tu Fototeca.
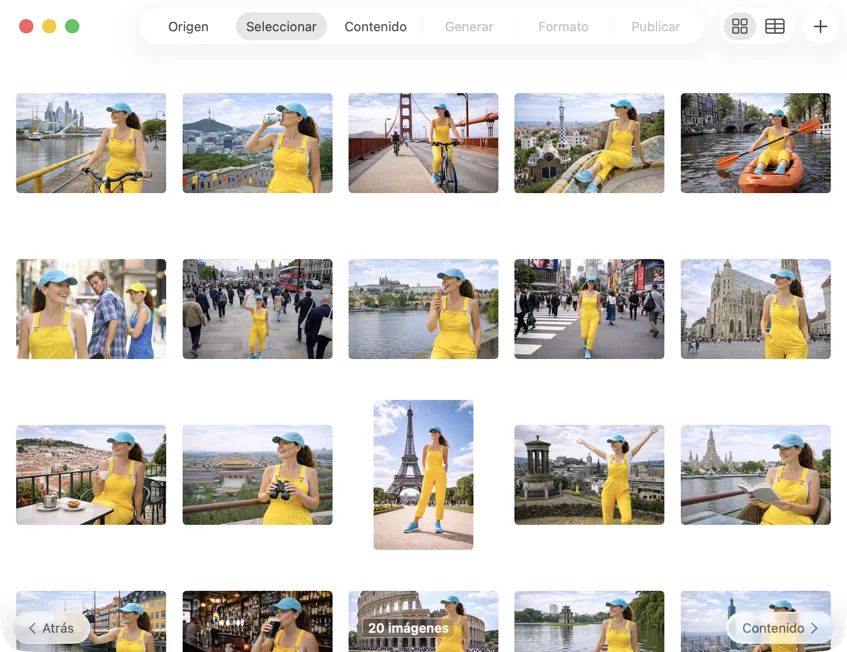
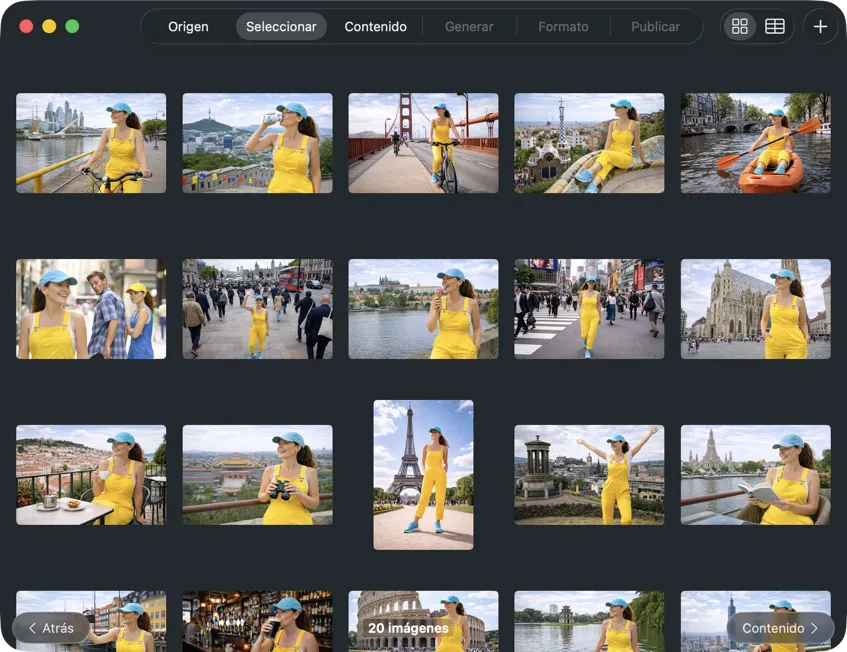
Elige exactamente qué quieres procesar. Revisa tu selección en vista de cuadrícula o tabla, añade más imágenes con el botón de añadir, o arrastra y suelta archivos en la app para crear un lote.
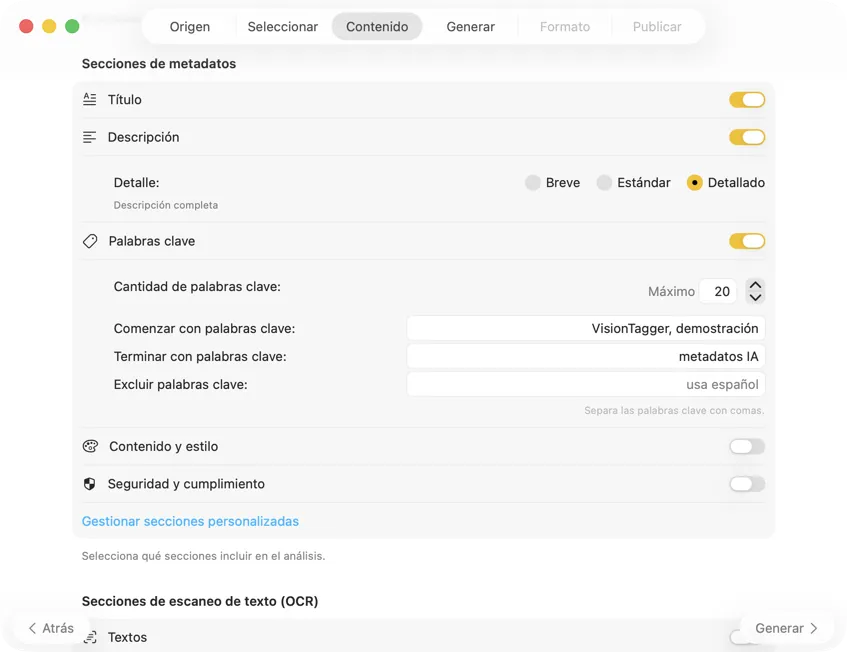
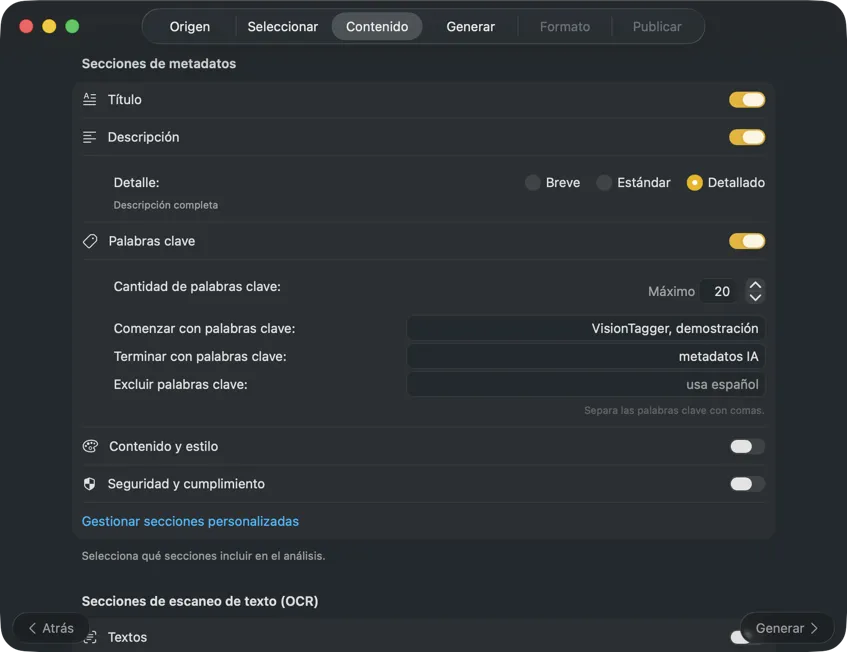
Elige un modelo de IA (descarga uno en la app con un clic) y selecciona qué metadatos generar: títulos, descripciones, palabras clave, etiquetas de estilo, clasificaciones de seguridad o tus propios campos personalizados.
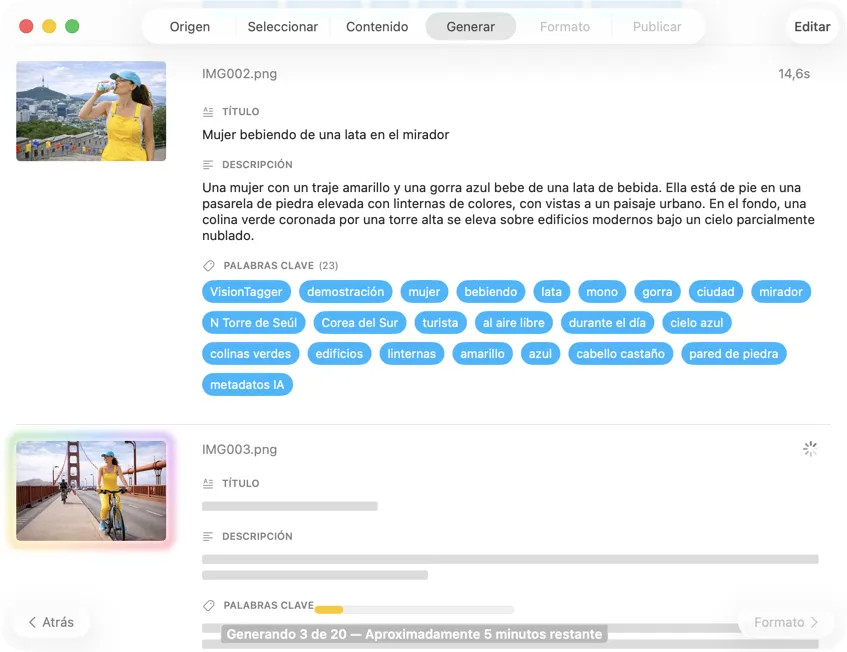
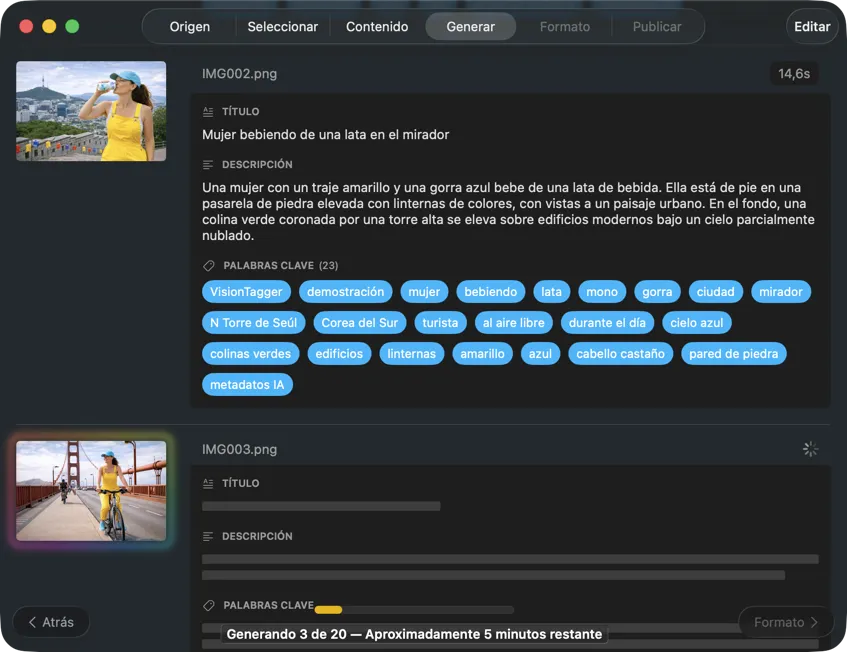
Mira cómo aparecen los resultados en tiempo real. VisionTagger procesa imágenes en local y transmite los metadatos generados a una lista con desplazamiento en cuanto cada elemento está listo, para que puedas revisar y editar salidas mientras el lote continúa.
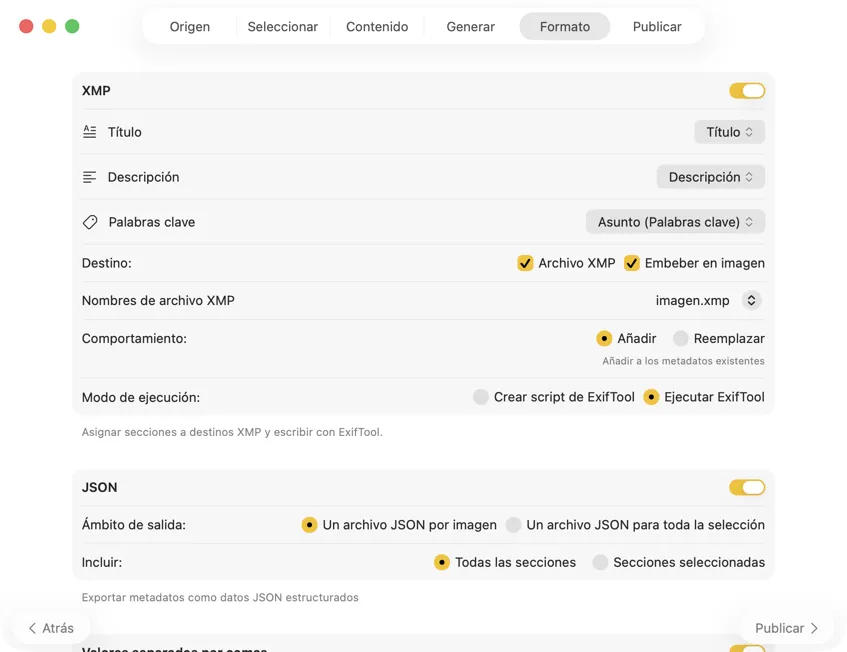
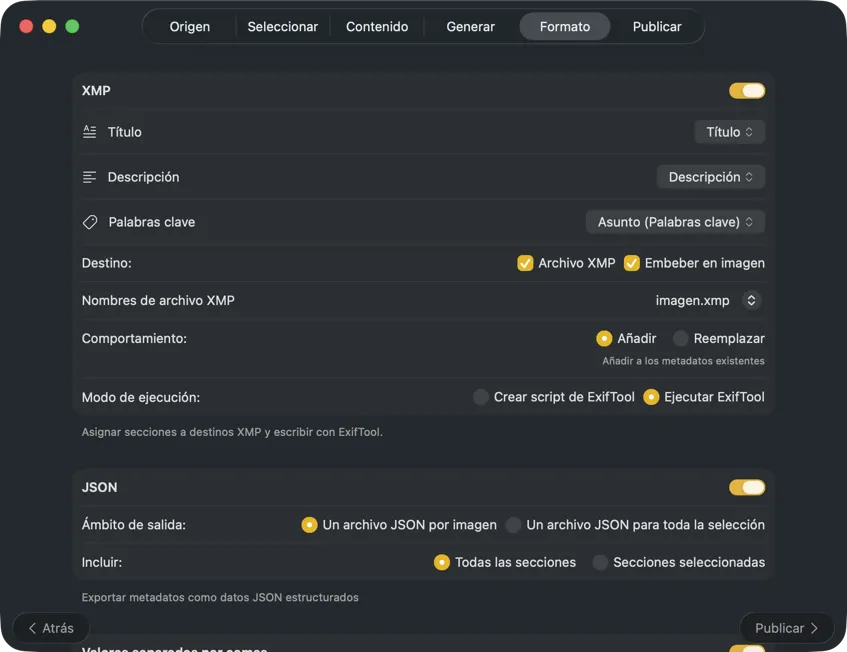
Elige adónde van los metadatos: sidecars XMP para tu catálogo de fotos, JSON o CSV para tu flujo web, etiquetas de Finder, o escribe de vuelta en Fotos. Selecciona varias salidas a la vez.
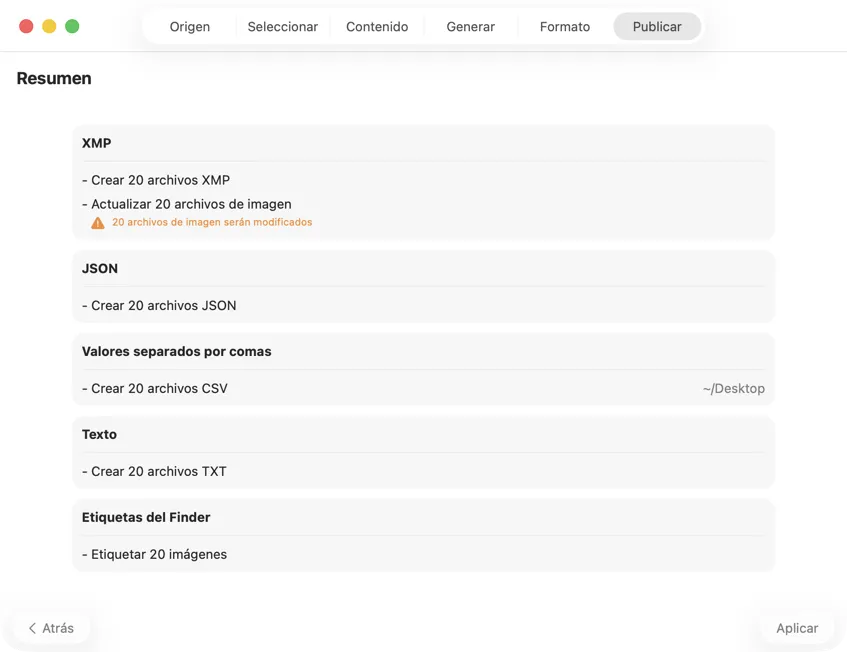
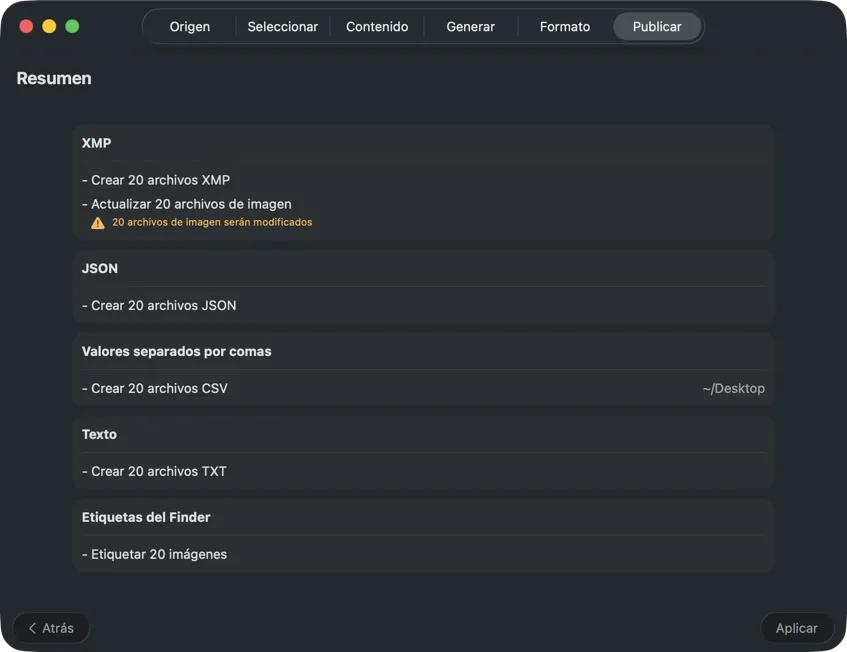
Confirma antes de que se escriba nada. Revisa un resumen claro de todas las acciones que se ejecutarán, incluyendo avisos cuando archivos o metadatos existentes puedan sobrescribirse — y luego publica para aplicar tus salidas seleccionadas con confianza.
Compra única
IVA incluido (excepto US & CA)
Pago seguro a través de FastSpring